このチュートリアルでは、コーディングのデモに入る前に、BERT 言語モデルがどのように機能するかを詳しく調べます。次に、特定のテキスト分類タスク用にモデルを微調整する方法を示しました。
8ヶ月前 • 17 分で読めます
目次

特に深層学習のサブドメインにおける人工知能の素晴らしさは、進歩が進むにつれて毎月数多くの成果を上げており、常に進歩しています。私の記事の多くは、主にディープ ラーニングの 2 つの重要なサブドメイン、つまりコンピューター ビジョンと自然言語処理 (NLP) に焦点を当てています。NLP は、言語のタスク、文法、および言語の意味理解に焦点を当てています。深層学習モデルを利用して、テキストや文章の特定のコンテキストの複雑な詳細と特定のパターンを AI がデコードするためのパターンを思いつくことができるようにします。そのために、テキスト分類、言語の翻訳 (機械翻訳)、チャットボット、
これらの種類のタスクを解決するための一般的な方法には、sequence-to-sequence モデル、アテンション メカニズムのユーティリティ、トランスフォーマー、およびその他の同様の一般的な手法が含まれます。この記事では、トランスフォーマーの最も成功したバリエーションの 1 つである、トランスフォーマーからの双方向エンコーダー表現 (BERT) に主に焦点を当てます。開始するために必要な基本的な概念のほとんどを理解し、この BERT アーキテクチャを利用して自然言語処理の問題のソリューションを計算します。以下の目次は、このブログ投稿で説明する機能のリストを示しています。コードを並行して実行するには、Paperspace の Gradient プラットフォームを利用することをお勧めします。
序章:
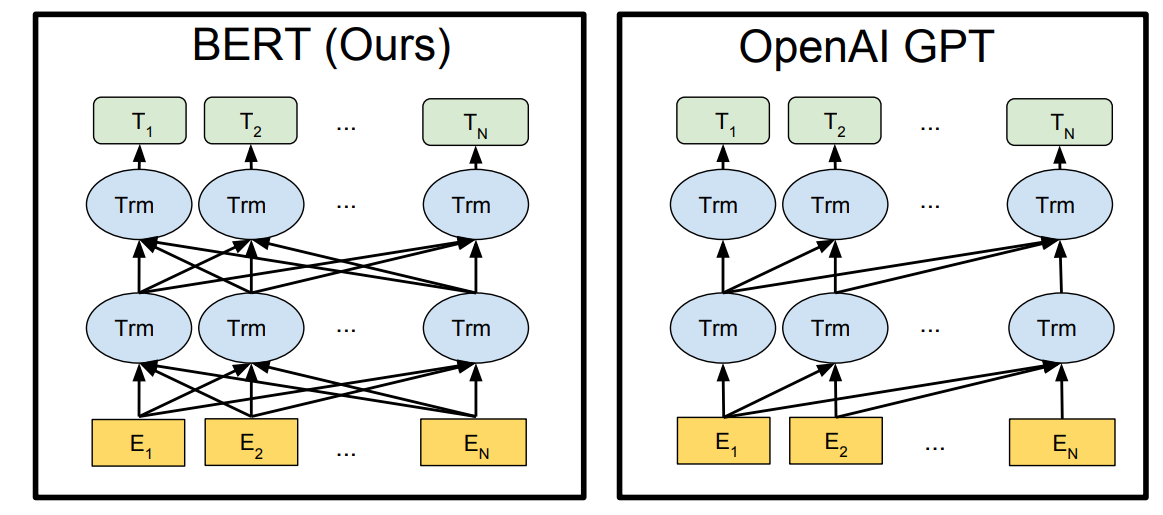
自然言語処理に関連するタスクのほとんどは、最初は単純な LSTM (長短期記憶) ネットワークの助けを借りて解決されました。これらのレイヤーは互いに積み重ねられて、ベクター ワードの学習プロセスが生成されます。ただし、これらのネットワークだけでは、高品質の結果を生成するには不十分であり、ニューラル機械翻訳やテキスト分類タスクなど、より精度が必要なタスクやプロジェクトでは失敗しました。単純な LSTM がこのように失敗する主な理由は、それらが低速でぎこちないネットワークであることです。また、LSTM のバリエーションは完全に双方向ではありません。したがって、学習プロセスを進めていくと、単語ベクトルのコンテキストと真の意味が失われます。
これらのタスクにおける画期的な革命の 1 つは、変圧器の導入により 2017 年に発生しました。「 Attention is all you need 」という研究論文で発表されたこれらの変換ネットワークは、単純な LSTM アーキテクチャで既存の問題に対処する独自のアプローチにより、自然言語処理の世界に革命をもたらしました。以前の記事の 1 つで、トランスフォーマーの概念を非常に詳細に取り上げました。次のリンクからこのブログをチェックすることを強くお勧めします。次のセクションで、変圧器ネットワークと BERT アーキテクチャの間に密接な関係があることを学習します。
ただし、現時点では、トランスフォーマーのエンコーダー ネットワークを無視してトランスフォーマー ネットワークの多数のデコーダー レイヤーをスタックすると、Generative Pre-trained Transformer (GPT)モデルが得られることに注意することが重要です。この人気のあるアーキテクチャには、GPT-2 および GPT-3 ネットワークでさらにいくつかのバリエーションがあり、以前の各バージョンで常に改善されています。ただし、トランスフォーマーのデコーダー ネットワークを無視して、トランスフォーマー モデルのエンコーダー セクションをスタックすると、トランスフォーマーからの双方向エンコーダー表現 (BERT)が得られます。次のセクションでは、より詳細に説明し、多くの問題を簡単に解決できる BERT トランスフォーマーの動作メカニズムを理解します。
BERT トランスフォーマーを理解する:
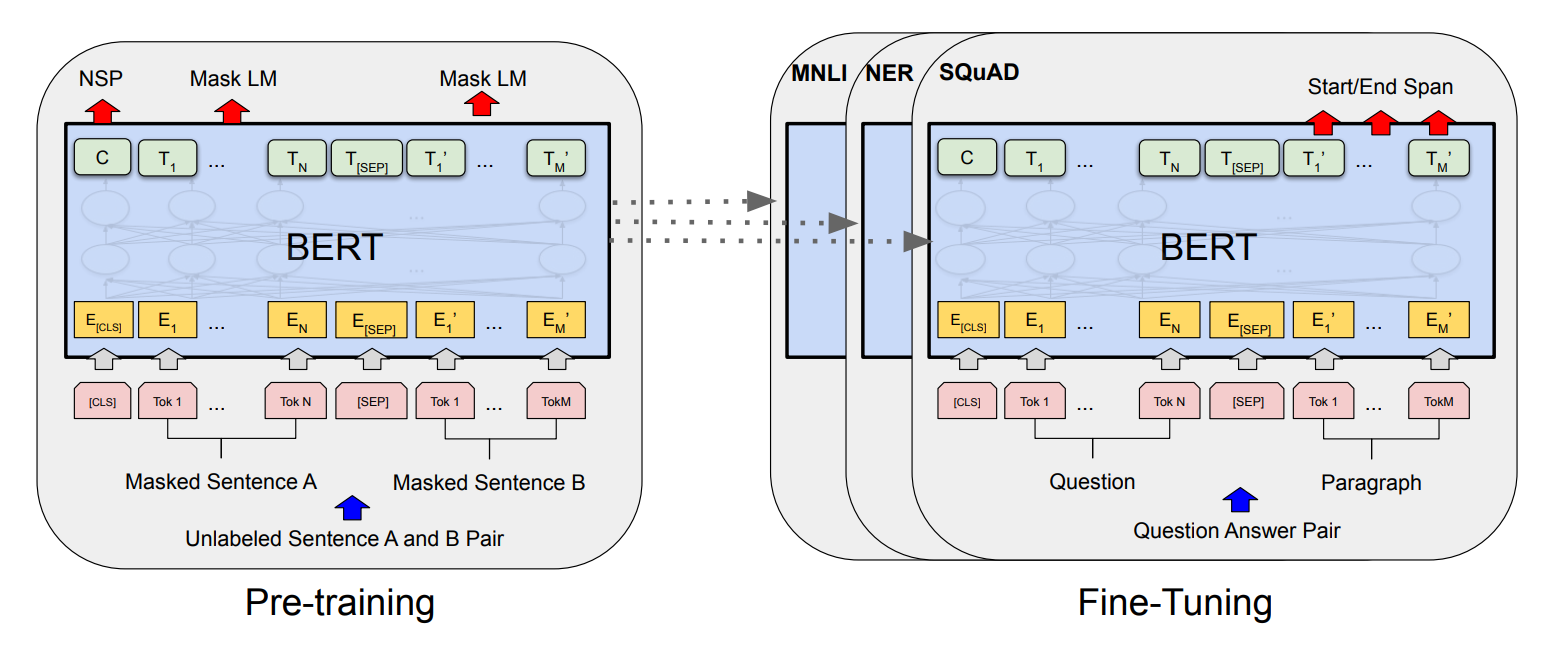
単純な LSTM ネットワークとは異なり、BERT トランスフォーマーはかなり複雑な方法で言語を理解できます。トランスフォーマー アーキテクチャでは、個々のエンコーダー ネットワークとデコーダー ブロックの両方が言語を理解する機能を備えています。したがって、これらの層のいずれかを積み重ねると、生成されたネットワークが言語を理解して学習できるシナリオが得られます。しかし、さまざまな自然言語処理タスクを実行するために、これらの BERT モデルがどの程度正確にトレーニングおよび利用されているかという疑問が生じます。
BERT のトレーニング プロセスは、主に 2 つのフェーズ、つまり BERT モデルの事前トレーニングと BERT モデルの微調整で構成されます。事前トレーニングのステップでの主な目的は、BERT モデルに言語の理解を教えることです。このプロセスは、半教師あり学習アプローチを使用して行われます。つまり、Web またはその他のリソースから収集された大量の情報に基づいてデータをトレーニングします。BERT モデルの事前トレーニング ステップでは、コンテキスト (または言語) を理解するためのマスク言語モデル (MLM) と次の文の予測 (NSP) を含む 2 つのタスクが同時に実行されます。
マスク言語モデル (MLM) では、マスクを使用して文のデータの一部 (約 15%) を非表示にし、モデルが文のコンテキストをよりよく理解できるようにします。目標は、これらのマスクされたトークンを出力して、双方向性を利用して目的の言語理解を実現することです。Next Sentence Prediction (NSP) の場合、BERT モデルは 2 つの文を考慮し、2 番目の文が最初の文の適切なフォローアップであるかどうかを判断します。
事前トレーニングの助けを借りて、BERT モデルはコンテキストと言語の理解を達成することができます。ただし、実行しようとしている特定のタスクに使用するには、微調整の 2 番目のステップが必要です。BERT モデルの微調整では、完全に接続された出力層を新しい層のネットワークに置き換えます。BERT モデルの微調整ステップは、教師あり学習タスクであり、特定のタスクを達成するためにモデルをトレーニングします。
ネットワークはすでに事前トレーニングされているため、新しいネットワークのみをトレーニングする必要があるため、微調整ステップは比較的高速になりますが、他の重みは特定のプロジェクトに応じてわずかに変更 (微調整) されます。これらの特定のタスクについては、この記事のアプリケーション セクションで説明します。とりあえず、BERT を使用したレビュー スコア分類プロジェクトの開発に進みましょう。
TensorFlow-Hub を使用して BERT でプロジェクトを開発する:
この記事のこのセクションでは、TensorFlow Hub から入手できる事前トレーニング済みの BERT モデルをロードし、この BERT モデルに追加の転移学習レイヤーを追加して、テキスト分類用のプロジェクトを構築する方法の詳細な内訳を探ります。この記事では、TensorFlow と Keras の深層学習フレームワークを利用します。これらのライブラリに慣れていない場合、またはこれらのトピックをすばやくブラッシュアップする場合は、以前のブログからこれらのライブラリの両方を確認することを強くお勧めします。必要なライブラリをインポートして、BERT 作業パイプラインの作成を始めましょう。
必要なライブラリのインポート:
TensorFlow ディープ ラーニング フレームワークは、TensorFlow Hub インポートと共に、このプロジェクトに不可欠です。TensorFlow Hub ライブラリを使用すると、開発者は事前にトレーニングされたモデルを読み込んで、多数のプロジェクトをさらに微調整およびデプロイできます。また、BERT モデルのプールされた出力レイヤーに追加するレイヤーをいくつかインポートし、これらの変更を使用して、テキスト分類タスクを実行するための転移学習モデルを作成します。
また、トレーニング済みのモデルを保存し、Tensor ボードでパフォーマンスを視覚化するために、いくつかの追加のコールバックを使用します。また、NumPy ライブラリ、システム コンポーネントにアクセスするための os ライブラリ、正規表現操作を規制するための re、不要なコメントを除外するための警告など、他のいくつかの基本的なインポートが使用されます。
#Importing the essential libraries
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Activation, Dropout, Flatten
from tensorflow.keras.layers import BatchNormalization, Conv2D, MaxPool2D
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau
from tensorflow.keras.callbacks import LearningRateScheduler, TensorBoard
from datetime import datetime
from sklearn.metrics import roc_auc_score
import numpy as np
import pandas as pd
from tqdm import tqdm
import os
import re
import warnings
warnings.filterwarnings("ignore")コピー
データセットの準備:
以下のKaggleリンクから取得できるAmazon Fine Food Reviewsデータセットを利用します。以下は、データセットと、データを読み取って理解するための対応するコード スニペットの簡単な説明です。プロジェクトを構築している作業ディレクトリにファイルが配置されていることを確認します。
このデータセットは、Amazon の高級食品のレビューで構成されています。データは、2012 年 10 月までの約 500,000 件のレビューすべてを含む、10 年以上の期間に及びます。レビューには、製品とユーザーの情報、評価、プレーン テキストのレビューが含まれます。また、他のすべての Amazon カテゴリからのレビューも含まれます。-
#Read the dataset - Amazon fine food reviews
reviews = pd.read_csv("Reviews.csv")
#check the info of the dataset
reviews.info()コピー
次のステップでは、テキスト情報とそれぞれのスコアのみを取得しながら、不要な「非数」(NAN) 値を除外します。
# Retrieving only the text and score columns while drop NAN values
reviews = reviews.loc[:, ['Text', 'Score']]
reviews = reviews.dropna(how='any')
reviews.head(1)コピー

次のステップでは、ニュートラル スコアを省略して、テキスト データのスコアを、否定的または肯定的なレビューのみのバイナリ分類タスクに変換します。ニュートラル スコア、つまり値が 3 のスコアは削除されます。これは自然言語処理のバイナリ分類タスクであるため、中立的なレビューは避けようとしています。値が 2 未満のすべてのスコアは否定的なレビューと見なされ、値が 3 を超えるすべてのスコアは肯定的なレビューと見なされます。
reviews.loc[reviews['Score'] <= 2, 'Score'] = 0
reviews.loc[reviews['Score'] > 3, 'Score'] = 1
reviews.drop(reviews[reviews['Score']==3].index, inplace=True)
reviews.shapeコピー
(525814, 2)
コピー
次のステップでは、データセットに必要な前処理を実行します。2 つの関数を作成します。最初の関数は最初の 50 語のみを取得できるようにし、2 番目の関数はトレーニング プロセスに不要な不要な文字の一部を削除できるようにします。関数を呼び出して、新しいデータセットを取得できます。以下は、前処理後のコード ブロックとサンプル データセットです。
def get_wordlen(x):
return len(x.split())
reviews['len'] = reviews.Text.apply(get_wordlen)
reviews = reviews[reviews.len<50]
reviews = reviews.sample(n=100000, random_state=30)
def remove_html(text):
html_pattern = re.compile('<.*?>')
return html_pattern.sub(r'', text)
text=reviews['Text']
preprocesstext=text.map(remove_html)
reviews['Text']=preprocesstext
#print head 5
reviews.head(5)コピー

以下は、層化サンプリングと特定のランダム状態でデータを分割するためのコード ブロックです。階層化されたサンプリング分割により、トレーニング データとテスト データの両方でバランスの取れた 0 と 1 のカウントを維持できます。つまり、適切なバイナリ構成が維持されます。ランダムな状態の指定により、さまざまなシステムやプラットフォームにわたって変化しない方法で結果を簡単に追跡できます。以下は、データセットとそれぞれのトレーニング プロットとテスト プロットを分割するためのコード スニペットです。
# Split the data into train and test data(20%) with Stratify sampling and random state 33
from sklearn.model_selection import train_test_split
X = reviews['Text']
y = reviews["Score"].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, stratify=y, random_state = 33)コピー
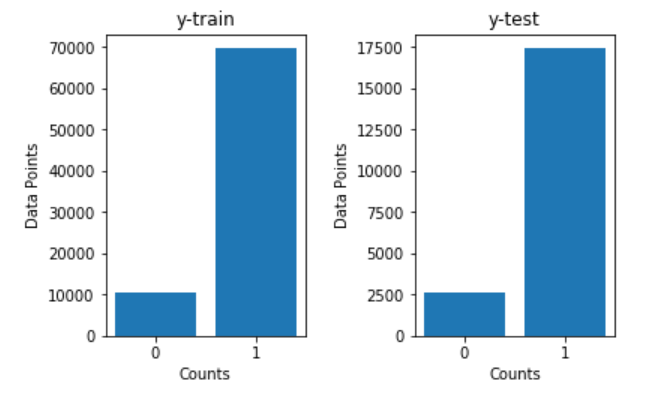
最後に、このセクションで実行したすべての手順の後、データを前処理済みの CSV ファイルの形式で作業ディレクトリに保存し、必要に応じてさらに計算を進めることができます。
# Saving to disk. if we need, we can load preprocessed data directly.
reviews.to_csv('preprocessed.csv', index=False)コピー
このプロジェクトに命を吹き込む
BERT モデルの開発:
このプロジェクトでは、以下の TensorFlow Hubウェブサイトから取得できる BERT uncased モデルを使用します。L=12 の隠れ層 (すなわち、Transformer ブロック)、H=768 の隠れサイズ、および A=12 の注意ヘッドを使用します。前のセクションで説明したように、事前トレーニング済みの BERT モデルを使用しながら、マスクされた入力も渡します。BERT モデルから目的の出力を取得し、それに対してさらに転移学習操作を実行できます。
## Loading the Pretrained Model from tensorflow HUB
tf.keras.backend.clear_session()
max_seq_length = 55
# Creating the necessary requirements
input_word_ids = tf.keras.layers.Input(shape=(max_seq_length,), dtype=tf.int32, name="input_word_ids")
input_mask = tf.keras.layers.Input(shape=(max_seq_length,), dtype=tf.int32, name="input_mask")
segment_ids = tf.keras.layers.Input(shape=(max_seq_length,), dtype=tf.int32, name="segment_ids")
#bert layer
bert_layer = hub.KerasLayer("https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/1", trainable=False)
pooled_output, sequence_output = bert_layer([input_word_ids, input_mask, segment_ids])
bert_model = Model(inputs=[input_word_ids, input_mask, segment_ids], outputs=pooled_output)
bert_model.summary()コピー
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_word_ids (InputLayer) [(None, 55)] 0 []
input_mask (InputLayer) [(None, 55)] 0 []
segment_ids (InputLayer) [(None, 55)] 0 []
keras_layer (KerasLayer) [(None, 768), 109482241 ['input_word_ids[0][0]',
(None, 55, 768)] 'input_mask[0][0]',
'segment_ids[0][0]']
==================================================================================================
Total params: 109,482,241
Trainable params: 0
Non-trainable params: 109,482,241
__________________________________________________________________________________________________
コピー
事前トレーニング済みの BERT モデルを取得したら、利用可能なデータに対して最終的なトークン化を行い、達成しようとしている特定のタスクに貢献するために微調整される最終モデルを開発することができます。
トークン化:
次のステップでは、データセットに対してトークン化アクションを実行します。この特定のアクションを計算するには、次の公式GitHubリンクから tokenization.py という名前の前処理ファイルをダウンロードすることが不可欠です ( wgetGradient でターミナルを使用して raw ファイルを使用します)。次のファイルをダウンロードして作業ディレクトリに配置したら、それをメイン プロジェクト ファイルにインポートできます。以下のコード ブロックでは、大きなデータを BERT モデルの有用で理解しやすい情報の小さなチャンクに変換します。
レビューをトークン化し、ハLSハLS(分類)とSえPSえP(セパレーター) トークンの開始時と終了時のそれぞれの操作。そうすることで、BERT モデルが各センテンスの開始と終了を区別するのに役立ち、バイナリ分類や次のセンテンス予測プロジェクトで役立つことがよくあります。形状の不一致を避けるためにパディングを追加することもできます。最後に、以下のコード ブロックに示すように、トレーニング データとテスト データの作成に進みます。
#getting Vocab file
vocab_file = bert_layer.resolved_object.vocab_file.asset_path.numpy()
do_lower_case = bert_layer.resolved_object.do_lower_case.numpy()
#import tokenization from the GitHub link provided
import tokenization
tokenizer = tokenization.FullTokenizer(vocab_file, do_lower_case)
X_train=np.array(X_train)
# print(X_train[0])
X_train_tokens = []
X_train_mask = []
X_train_segment = []
X_test_tokens = []
X_test_mask = []
X_test_segment = []
def TokenizeAndConvertToIds(text):
tokens= tokenizer.tokenize(reviews) # tokenize the reviews
tokens=tokens[0:(max_seq_length-2)]
tokens=['[CLS]',*tokens,'[SEP]'] # adding cls and sep at the end
masked_array=np.array([1]*len(tokens) + [0]* (max_seq_length-len(tokens))) # masking
segment_array=np.array([0]*max_seq_length)
if(len(tokens)<max_seq_length):
padding=['[PAD]']*(max_seq_length-len(tokens)) # padding
tokens=[*tokens,*padding]
tokentoid=np.array(tokenizer.convert_tokens_to_ids(tokens)) # converting the tokens to id
return tokentoid,masked_array,segment_array
for reviews in tqdm(X_train):
tokentoid,masked_array,segment_array=TokenizeAndConvertToIds(reviews)
X_train_tokens.append(tokentoid)
X_train_mask.append(masked_array)
X_train_segment.append(segment_array)
for reviews in tqdm(X_test):
tokentoid,masked_array,segment_array=TokenizeAndConvertToIds(reviews)
X_test_tokens.append(tokentoid)
X_test_mask.append(masked_array)
X_test_segment.append(segment_array)
X_train_tokens = np.array(X_train_tokens)
X_train_mask = np.array(X_train_mask)
X_train_segment = np.array(X_train_segment)
X_test_tokens = np.array(X_test_tokens)
X_test_mask = np.array(X_test_mask)
X_test_segment = np.array(X_test_segment)コピー
すべてのトークンを正常に作成したら、それらを pickle ファイルに保存して、必要な将来の計算のためにそれらをリロードすることをお勧めします。これは、ダンプ機能とロード機能の両方を示す以下のコード スニペットから実行できます。
import pickle
# save all your results to disk so that, no need to run all again.
pickle.dump((X_train, X_train_tokens, X_train_mask, X_train_segment, y_train),open('train_data.pkl','wb'))
pickle.dump((X_test, X_test_tokens, X_test_mask, X_test_segment, y_test),open('test_data.pkl','wb'))
# you can load from disk
X_train, X_train_tokens, X_train_mask, X_train_segment, y_train = pickle.load(open("train_data.pkl", 'rb'))
X_test, X_test_tokens, X_test_mask, X_test_segment, y_test = pickle.load(open("test_data.pkl", 'rb')) コピー
BERT での転移学習モデルのトレーニング:
データの前処理、BERT モデルの事前トレーニング、およびデータのトークン化が完了したら、微調整されたアーキテクチャ モデルを開発して、転移学習モデルの作成に進むことができます。まず、トークン、マスク、およびそれぞれのセグメントを渡して、トレーニング データの出力を取得しましょう。
# get the train output with the BERT model
X_train_pooled_output=bert_model.predict([X_train_tokens,X_train_mask,X_train_segment])コピー
同様に、以下のコード スニペットに示すように、テスト データに対しても BERT モデルを使用して予測を実行します。
# get the test output with the BERT model
X_test_pooled_output=bert_model.predict([X_test_tokens,X_test_mask,X_test_segment])コピー
次のステップでは、pickle ライブラリを使用して予測を保存できます。システム ハードウェアによっては、前の 2 つの予測ステップの実行に少し時間がかかる場合があることに注意してください。予測出力を正常に保存して pickle ファイルにダンプしたら、ステートメントをコメントアウトします。その後、再び pickle ライブラリを使用して、将来の計算のためにデータをロードできます。
# save all the results to the respective folder to avoid running the previous predictions again.
pickle.dump((X_train_pooled_output, X_test_pooled_output),open('final_output.pkl','wb'))
# load the data for second utility
X_train_pooled_output, X_test_pooled_output= pickle.load(open('final_output.pkl', 'rb'))コピー
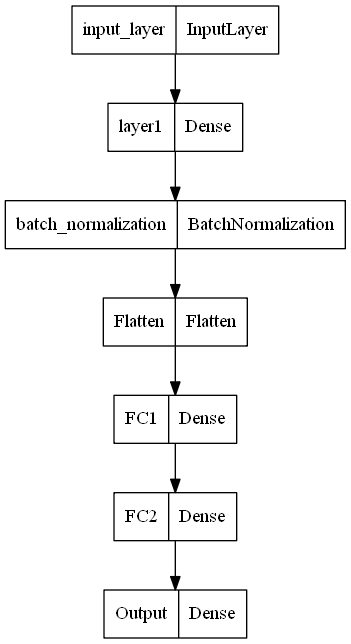
事前トレーニング済みの BERT モデルに微調整レイヤーとして追加できるカスタム アーキテクチャを作成します。768 個の入力フィーチャを含む入力レイヤー、指定されたパラメーターの密集レイヤー、バッチ正規化レイヤー、平坦化レイヤーを追加します。最後に、連続する 3 つの完全に接続されたレイヤーを使用して、ネットワークを完成させます。
最終的な出力レイヤーは、2 値分類タスクであるため、1 つの出力ノードでシグモイド活性化関数を使用し、結果の出力が正か負かを予測する必要があります。機能的な API タイプ モデリングを使用して、レイヤーとアーキテクチャ ビルドをより細かく制御できるようにしました。このステップでは、代わりにシーケンス モデリング構造を使用することもできます。
# input layer
input_layer=Input(shape=(768,), name='input_layer')
# Dense layer
layer1 = Dense(50,activation='relu',kernel_initializer=tf.keras.initializers.RandomUniform(0,1), name='layer1')(input_layer)
# MaxPool Layer
Normal1 = BatchNormalization()(layer1)
# Flatten
flatten = Flatten(data_format='channels_last',name='Flatten')(Normal1)
# FC layer
FC1 = Dense(units=30,activation='relu',kernel_initializer=tf.keras.initializers.glorot_normal(seed=32),name='FC1')(flatten)
# FC layer
FC2 = Dense(units=30,activation='relu',kernel_initializer=tf.keras.initializers.glorot_normal(seed=33),name='FC2')(FC1)
# output layer
Out = Dense(units=1,activation= "sigmoid", kernel_initializer=tf.keras.initializers.glorot_normal(seed=3),name='Output')(FC2)
model = Model(inputs=input_layer,outputs=Out)コピー
転移学習の微調整モデルが作成されたら、いくつかの重要なコールバックを呼び出してモデルを保存し、それに応じて結果を監視できます。ただし、トレーニング プロセスは非常に高速であるため、これらのコールバックのいくつかは必要ない場合があります。得られた結果のより正確な説明を表すため、このモデルの AUROC スコアを監視します。
checkpoint = ModelCheckpoint("best_model1.hdf5", monitor='accuracy', verbose=1,
save_best_only=True, mode='auto', save_freq=1)
reduce = ReduceLROnPlateau(monitor='accuracy', factor=0.2, patience=2, min_lr=0.0001, verbose = 1)
def auroc(y_true, y_pred):
return tf.py_function(roc_auc_score, (y_true, y_pred), tf.double)
logdir = os.path.join("logs", datetime.now().strftime("%Y%m%d-%H%M%S"))
tensorboard_Visualization = TensorBoard(log_dir=logdir, histogram_freq=1)コピー
最後に、モデルをコンパイルしてトレーニングできます。コンパイルには、Adam オプティマイザー、バイナリ クロス エントロピー損失、および精度と AUROC メトリックを利用します。以下のコード ブロックで説明されているように、300 のバッチ サイズと必要なコールバックで 10 エポックのモデルをトレーニングします。
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy', auroc])
model.fit(X_train_pooled_output, y_train,
validation_split=0.2,
epochs=10,
batch_size = 300,
callbacks=[checkpoint, reduce, tensorboard_Visualization])コピー
以下は、概念をよりよく理解するために作成したモデルのプロットです。このネットワークは、テキスト分類の特定のタスクを実行するための微調整ステップとして、BERT アーキテクチャの上に構築されます。
tf.keras.utils.plot_model(
model, to_file='model1.png', show_shapes=False, show_layer_names=True,
rankdir='TB', expand_nested=False, dpi=96
)コピー
次のステップでは、モデルのトレーニング プロセスのパフォーマンスを視覚化します。テンソル ボードで魔法の関数を使用し、現在の作業ディレクトリに保存されているログ フォルダーへのパスを指定します。外部テンソル ボード エクステンションを実行すると、さまざまなグラフを表示できます。ただし、AUROC スコアは、モデルのパフォーマンスのほぼ正確な説明を表しているため、心配しています。以下は、次のタスクのグラフです。
%load_ext tensorboard
%tensorboard --logdir logsコピー
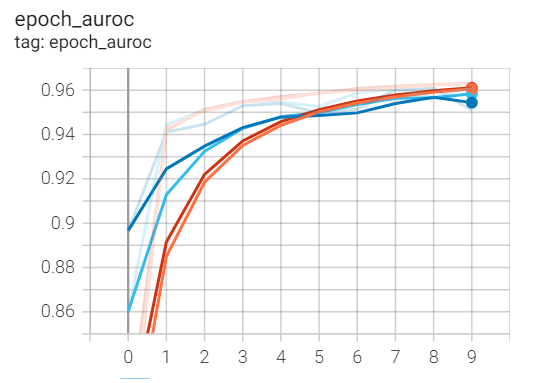
BERT モデルの多数の反復とバリエーションを試して、特定のユース ケースに最適なタイプのモデルを確認することをお勧めします。このセクションでは、BERT モデルを使用してバイナリ テキスト分類の問題を解決する方法について説明しました。しかし、BERT のアプリケーションは、このタスクに限定されません。次のセクションでは、BERT のいくつかのアプリケーションについてさらに詳しく説明します。
BERT のアプリケーション:
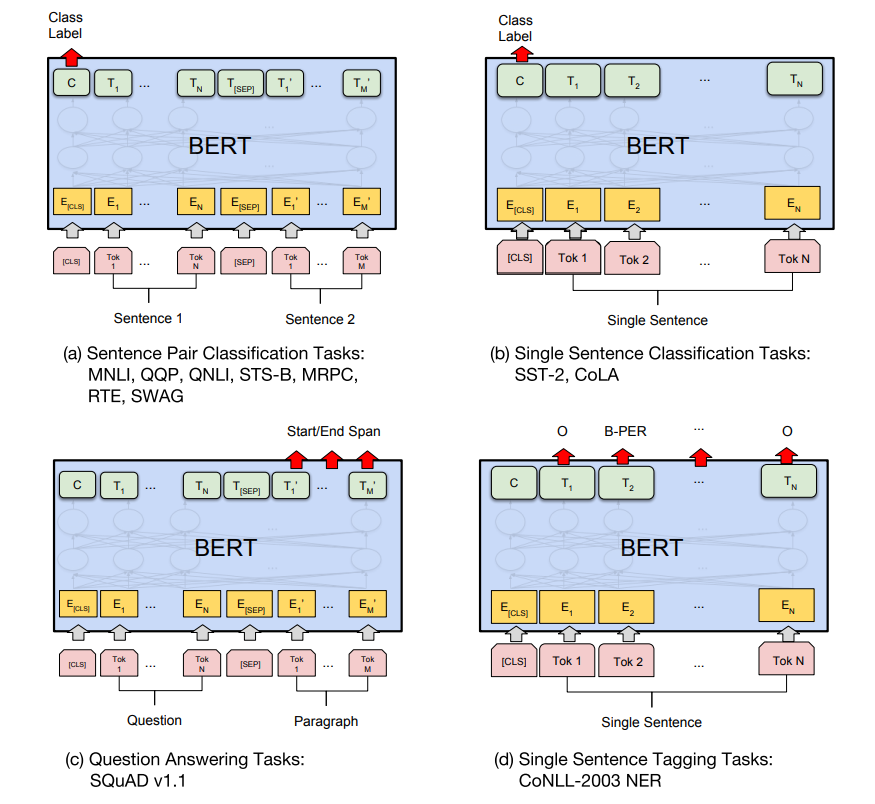
BERT トランスには数多くのアプリケーションがあります。これらのネットワークがどのように機能するかを要約すると、さまざまなタスクを解決するために利用できる事前トレーニング済みの BERT モデルがあります。2 番目のステップでは、BERT モデルを使用して、実行しようとしているタスクまたはアプリケーションのタイプを決定する微調整レイヤーを追加します。BERT のより一般的なアプリケーションのいくつかを見てみましょう。
- テキスト分類– この記事では、BERT トランスフォーマーをテキスト分類に使用する方法について説明します。最終的な BERT モデルは、最終的なシグモイド活性化関数に応じて微調整され、任意の文のバイナリ分類出力が生成されました。
- 質問応答タスク– BERT モデルを使用して質問と回答の検索を実行することもできます。のハLSハLSとSえPSえPトークンは質問の最初と最後に使用でき、他の段落は答えを表します。そのようなタスクを実行するために、それに応じてモデルをトレーニングできます。
- ニューラル機械翻訳– BERT モデルは、機械翻訳のタスクにも役立ちます。機械翻訳では、アーキテクチャを利用して、ある言語で入力された情報を別の言語に翻訳できます。特定の言語入力を使用してモデルをトレーニングし、適切な翻訳済み出力にすることができます。
- 感情分析– テキスト分類と同様に、BERT モデルを使用してさまざまな感情を分類できます。ポジティブ、ネガティブ、ニュートラルなどの感情を分類するだけでなく、そのようなプロジェクトを実行するためのデータの正しいコンテキストを使用して、人間が示す他のいくつかの感情に拡張することもできます。
これらの 4 つの主要なアプリケーションとは別に、BERT モデルを利用して望ましい結果を達成できる自然言語処理アプリケーションが多数あります。この分野は膨大で、取り組むべきタスクやプロジェクトは多岐にわたります。視聴者には、さらに多くのアプリケーションをチェックして、この記事で既に説明したアプリケーションを試してみることをお勧めします。
結論:

ソーシャル メディアの急激な台頭により、特にディープ ラーニングの分野における人工知能の能力は、かつてないほど高まっています。これらの深層学習モデルが NLP 問題を解決するための効果的なソリューションを生成および計算するという要件は、企業が製品を改善するために重要です。単純な LSTM アーキテクチャでディープ ラーニングの初期の時代に NLP に関連するタスクに対処して取り組むことは困難でしたが、2017 年代と 2018 年代にトランスフォーマー ネットワークが導入された革命的な時期がありました。この時代には、BERTモデルを含む複数の言語モデルが構築され、非常に効果的な結果が得られました。
この記事では、トランスフォーマーからの双方向エンコーダー表現 (BERT)の動作の背後にある動作概念を説明する前に、ディープ ラーニングを使用した NLP の簡単な歴史を説明しました。それらの機能の詳細なメカニズムを調べた後、これらのモデルが最適に実行できる自然言語処理タスクの種類を調べました。BERT アーキテクチャの基本的な理解に基づいて、TensorFlow-Hub の助けを借りて BERT モデルを構築し、テキスト分類のタスクを実行して、非常に優れた結果を生み出しました。最後に、現代の業界が高品質の結果を達成するために利用している BERT の最も重要なアプリケーションのいくつかを分析しました。

コメント