NLP の最先端の言語モデル
BERT (Bidirectional Encoder Representations from Transformers) は、 Google AI Language の研究者によって最近公開された論文です。質問応答 (SQuAD v1.1)、自然言語推論 (MNLI) などを含むさまざまな NLP タスクで最先端の結果を提示することにより、機械学習コミュニティに騒動を引き起こしました。
BERT の主要な技術革新は、人気のあるアテンション モデルである Transformer の双方向トレーニングを言語モデリングに適用することです。これは、テキスト シーケンスを左から右へ、または左から右と右から左のトレーニングを組み合わせて調べた以前の取り組みとは対照的です。この論文の結果は、双方向にトレーニングされた言語モデルは、単一方向の言語モデルよりも言語の文脈と流れをより深く理解できることを示しています。この論文では、研究者は、Masked LM (MLM) という名前の新しい手法について詳しく説明しています。これにより、以前は不可能だったモデルの双方向トレーニングが可能になります。
バックグラウンド
コンピューター ビジョンの分野では、研究者は転移学習の価値を繰り返し示してきました。つまり、ImageNet などの既知のタスクでニューラル ネットワーク モデルを事前トレーニングし、その後、トレーニング済みのニューラル ネットワークをベースとして微調整を実行します。用途に特化した新モデル。近年、研究者は、同様の手法が多くの自然言語タスクで役立つことを示してきました。
NLP タスクでも人気があり、最近の ELMo 論文で例示されている別のアプローチは、機能ベースのトレーニングです。このアプローチでは、事前にトレーニングされたニューラル ネットワークが単語の埋め込みを生成し、それが NLP モデルの特徴として使用されます。
BERT の仕組み
BERT は、テキスト内の単語 (またはサブワード) 間の文脈上の関係を学習するアテンション メカニズムである Transformer を利用します。通常の形式の Transformer には、テキスト入力を読み取るエンコーダーと、タスクの予測を生成するデコーダーという 2 つの別個のメカニズムが含まれています。BERT の目標は言語モデルを生成することであるため、必要なのはエンコーダー メカニズムだけです。Transformer の詳細な動作については、Googleの論文が掲載されています。
テキスト入力を順番に (左から右または右から左に) 読み取る方向モデルとは対照的に、Transformer エンコーダーは単語のシーケンス全体を一度に読み取ります。したがって、双方向であると見なされますが、無指向性であると言ったほうが正確です。この特性により、モデルはその周囲のすべて (単語の左右) に基づいて単語のコンテキストを学習できます。
以下のチャートは、Transformer エンコーダーの概要を示しています。入力は一連のトークンで、最初にベクトルに埋め込まれ、次にニューラル ネットワークで処理されます。出力はサイズ H の一連のベクトルであり、各ベクトルは同じインデックスを持つ入力トークンに対応します。
言語モデルをトレーニングする場合、予測目標を定義するという課題があります。多くのモデルは、シーケンス内の次の単語を予測します (例: 「The child came home from ___」)。これは、コンテキスト学習を本質的に制限する方向性アプローチです。この課題を克服するために、BERT は 2 つのトレーニング戦略を使用します。
マスクド LM (MLM)
単語シーケンスを BERT に入力する前に、各シーケンスの単語の 15% が [MASK] トークンに置き換えられます。次に、モデルは、シーケンス内の他のマスクされていない単語によって提供されるコンテキストに基づいて、マスクされた単語の元の値を予測しようとします。技術的に言えば、出力単語の予測には次のものが必要です。
- エンコーダー出力の上に分類レイヤーを追加します。
- 出力ベクトルを埋め込み行列で乗算し、それらを語彙次元に変換します。
- ソフトマックスを使用して語彙内の各単語の確率を計算します。

BERT 損失関数は、マスクされた値の予測のみを考慮し、マスクされていない単語の予測を無視します。結果として、モデルは指向性モデルよりも収束に時間がかかりますが、これはコンテキスト認識の向上によって相殺される特性です (要点 #3 を参照)。
注: 実際には、BERT の実装はもう少し複雑で、15% のマスクされた単語をすべて置き換えるわけではありません。
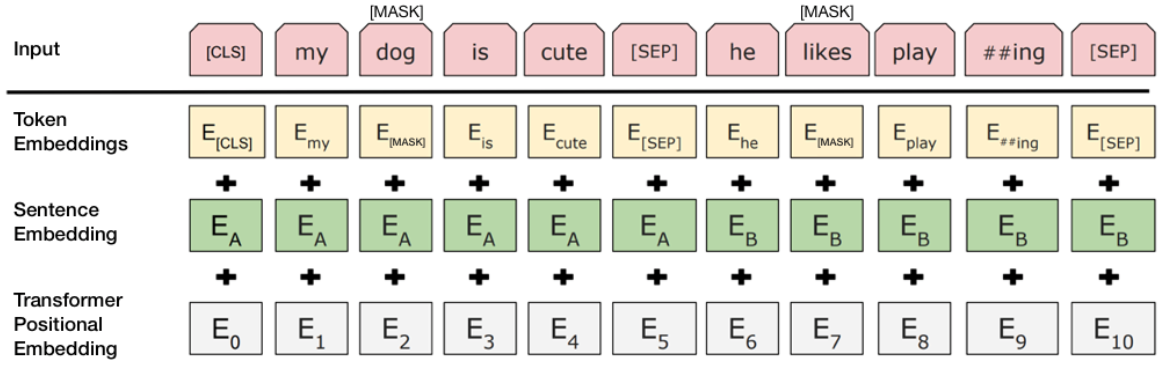
BERT トレーニング プロセスでは、モデルは入力として文のペアを受け取り、ペアの 2 番目の文が元のドキュメントの後続の文であるかどうかを予測することを学習します。トレーニング中、入力の 50% は、2 番目の文が元のドキュメントの後続の文であるペアであり、残りの 50% では、コーパスからのランダムな文が 2 番目の文として選択されます。ランダムな文が最初の文から切り離されることを前提としています。
モデルがトレーニングで 2 つの文を区別できるようにするために、入力はモデルに入る前に次の方法で処理されます。
- [CLS] トークンは最初の文の先頭に挿入され、[SEP] トークンは各文の最後に挿入されます。
- 各トークンには文Aまたは文Bを示す文埋め込みが付加される。文の埋め込みは、語彙が 2 のトークンの埋め込みと概念が似ています。
- 各トークンに位置埋め込みが追加され、シーケンス内の位置が示されます。位置埋め込みの概念と実装は、Transformer の論文で紹介されています。
2 番目の文が実際に最初の文に接続されているかどうかを予測するには、次の手順を実行します。
- 入力シーケンス全体が Transformer モデルを通過します。
- [CLS] トークンの出力は、単純な分類層 (重みとバイアスの学習済み行列) を使用して、2×1 の形状のベクトルに変換されます。
- softmax で IsNextSequence の確率を計算します。
BERT モデルをトレーニングする場合、Masked LM と Next Sentence Prediction は一緒にトレーニングされ、2 つの戦略の複合損失関数を最小化することを目標としています。
BERTの使い方(微調整)
特定のタスクに BERT を使用するのは比較的簡単です。
BERT は、コア モデルに小さなレイヤーを追加するだけで、さまざまな言語タスクに使用できます。
- 感情分析などの分類タスクは、[CLS] トークンの Transformer 出力の上に分類レイヤーを追加することで、次の文の分類と同様に実行されます。
- 質問応答タスク (例: SQuAD v1.1) では、ソフトウェアはテキスト シーケンスに関する質問を受け取り、シーケンス内の回答をマークする必要があります。BERT を使用すると、回答の開始と終了を示す 2 つの追加ベクトルを学習することで、Q&A モデルをトレーニングできます。
- Named Entity Recognition (NER) では、ソフトウェアはテキスト シーケンスを受け取り、テキストに表示されるさまざまな種類のエンティティ (人、組織、日付など) をマークする必要があります。BERT を使用すると、NER ラベルを予測する分類レイヤーに各トークンの出力ベクトルを供給することで、NER モデルをトレーニングできます。
微調整トレーニングでは、ほとんどのハイパーパラメーターは BERT トレーニングと同じままであり、ペーパーでは、調整が必要なハイパーパラメーターに関する具体的なガイダンス (セクション 3.5) が提供されています。BERT チームは、この手法を使用して、さまざまな困難な自然言語タスクで最先端の結果を達成しました。詳細については、論文のセクション 4 を参照してください。
お持ち帰り
- 巨大なスケールであっても、モデルのサイズは重要です。3 億 4500 万のパラメーターを持つ BERT_large は、この種の最大のモデルです。小規模なタスクでは、1 億 1000 万個のパラメーターしかない同じアーキテクチャを使用する BERT_base よりも明らかに優れています。
- 十分なトレーニング データがあれば、より多くのトレーニング ステップ == 精度が高くなります。たとえば、MNLI タスクでは、同じバッチ サイズの 500K ステップと比較して、1M ステップ (128,000 ワードのバッチ サイズ) でトレーニングすると、BERT_base の精度が 1.0% 向上します。
- BERT の双方向アプローチ (MLM) は、左から右へのアプローチよりも収束が遅くなります(各バッチで単語の 15% しか予測されないため) が、少数の事前トレーニング ステップの後でも、双方向トレーニングは左から右へのトレーニングよりも優れています。

計算に関する考慮事項 (トレーニングと適用)

結論
BERT は、間違いなく自然言語処理のための機械学習の使用におけるブレークスルーです。親しみやすく、素早い微調整が可能であるという事実により、将来的には幅広い実用的なアプリケーションが可能になるでしょう。この要約では、過度の技術的詳細に溺れることなく、論文の主なアイデアを説明しようとしました. より深く掘り下げたい場合は、記事全文とその中で参照されている補助記事を読むことを強くお勧めします。もう 1 つの有用なリファレンスは、BERT のソース コードとモデルです。これらは 103 の言語をカバーし、研究チームによって寛大にオープン ソースとしてリリースされました。
付録 A — 単語マスキング
BERT での言語モデルのトレーニングは、ランダムに選択された入力内のトークンの 15% を予測することによって行われます。これらのトークンは次のように前処理されます — 80% は「[MASK]」トークンに置き換えられ、10% はランダムな単語に置き換えられ、10% は元の単語を使用します。著者がこのアプローチを選択するに至った直感は次のとおりです (洞察を提供してくれた Google の Jacob Devlin に感謝します)。
- [MASK] を 100% 使用した場合、モデルは必ずしもマスクされていない単語の適切なトークン表現を生成しません。マスクされていないトークンは引き続きコンテキストに使用されましたが、モデルはマスクされた単語を予測するために最適化されました。
- [MASK] を 90% の確率で使用し、ランダムな単語を 10% の確率で使用すると、観察された単語が決して正しくないことをモデルに学習させることになります。
- [MASK] を 90% の確率で使用し、同じ単語を 10% の確率で保持した場合、モデルは文脈に依存しない埋め込みを自明にコピーできます。
このアプローチの比率ではアブレーションは行われておらず、別の比率の方が効果的だった可能性があります。さらに、モデルのパフォーマンスは、選択したトークンを 100% マスキングするだけではテストされていません。

コメント