
今年は、機械学習の見事なアプリケーションが見られました。OpenAI GPT-2は、現在の言語モデルが生成できると予想していたものを超える、首尾一貫した情熱的なエッセイを書くという印象的な能力を示しました。GPT-2 は、特に目新しいアーキテクチャではありませんでした。そのアーキテクチャは、デコーダのみのトランスフォーマーに非常に似ています。ただし、GPT2 は、大規模なデータセットでトレーニングされた非常に大規模な変換ベースの言語モデルでした。この投稿では、モデルが結果を生成できるようにしたアーキテクチャを見ていきます。その自己注意層の深みに入ります。そして、言語モデリングを超えたデコーダーのみのトランスフォーマーのアプリケーションを見ていきます。
ここでの私の目標は、以前の投稿The Illustrated Transformerを補足することでもあり、トランスフォーマーの内部動作と、元の論文からどのように進化したかを説明するビジュアルを追加することです。私の希望は、この視覚的な言語が、後の Transformer ベースのモデルの内部動作が進化し続けるにつれて、説明を容易にすることです。
コンテンツ
- パート 1: GPT2 と言語モデリング
- 言語モデルとは
- 言語モデリング用のトランスフォーマー
- BERTとの1つの違い
- トランスブロックの進化
- 脳外科の短期集中コース: GPT-2 の内部を見る
- より深い内観
- パート 1 の終了: GPT-2、ご列席の皆様
- パート 2: 図解された自己注意
- Self-Attention (マスキングなし)
- 1- クエリ、キー、および値のベクトルを作成する
- 2-スコア
- 3-合計
- イラスト化された仮面の自己注意
- GPT-2 仮面自己注意
- 言語モデリングを超えて
- あなたはそれを作りました!
- パート 3: 言語モデリングを超えて
- 機械翻訳
- 要約
- 転移学習
- ミュージックジェネレーション
パート #1: GPT2 と言語モデリング#
では、言語モデルとは正確には何なのでしょうか?
言語モデルとは
The Illustrated Word2vecでは、言語モデルとは何かについて説明しました。基本的には、文の一部を見て次の単語を予測できる機械学習モデルです。最も有名な言語モデルは、現在入力した内容に基づいて次の単語を提案するスマートフォンのキーボードです。
この意味で、GPT-2 は基本的にキーボード アプリの次の単語予測機能であると言えますが、携帯電話よりもはるかに大きく洗練された機能です。GPT-2 は、OpenAI の研究者が研究活動の一環としてインターネットからクロールした WebText と呼ばれる大規模な 40 GB のデータセットでトレーニングされました。ストレージ サイズを比較すると、私が使用しているキーボード アプリ SwiftKey は 78 MB のスペースを占有します。トレーニング済みの GPT-2 の最小のバリアントは、すべてのパラメーターを保存するために 500 MB のストレージを必要とします。最大の GPT-2 バリアントはサイズが 13 倍であるため、6.5 GB 以上のストレージ スペースを占有する可能性があります。

GPT-2 を試す優れた方法の 1 つは、AllenAI GPT-2 Explorerを使用することです。GPT-2 を使用して、次の単語の 10 個の可能な予測を (確率スコアと共に) 表示します。単語を選択すると、次の予測リストが表示され、パッセージを書き続けることができます。
言語モデリング用のトランスフォーマー
The Illustrated Transformerで見たように、元の Transformer モデルはエンコーダーとデコーダーで構成されており、それぞれが Transformer ブロックと呼ばれるもののスタックです。モデルは機械翻訳に取り組んでいたため、そのアーキテクチャは適切でした。これは、エンコーダー/デコーダー アーキテクチャーが過去に成功した問題です。
その後の研究作業の多くは、アーキテクチャがエンコーダーまたはデコーダーのいずれかを排除し、トランスフォーマー ブロックの 1 つのスタックのみを使用することを確認しました。実際に可能な限り高くスタックし、大量のトレーニング テキストを供給し、膨大な量の計算を実行します。それら (これらの言語モデルのいくつかをトレーニングするために数十万ドル、おそらくAlphaStarの場合は数百万ドル)。
これらのブロックをどのくらいの高さまで積み重ねることができますか? これが、さまざまな GPT2 モデル サイズを区別する主な要因の 1 つです。
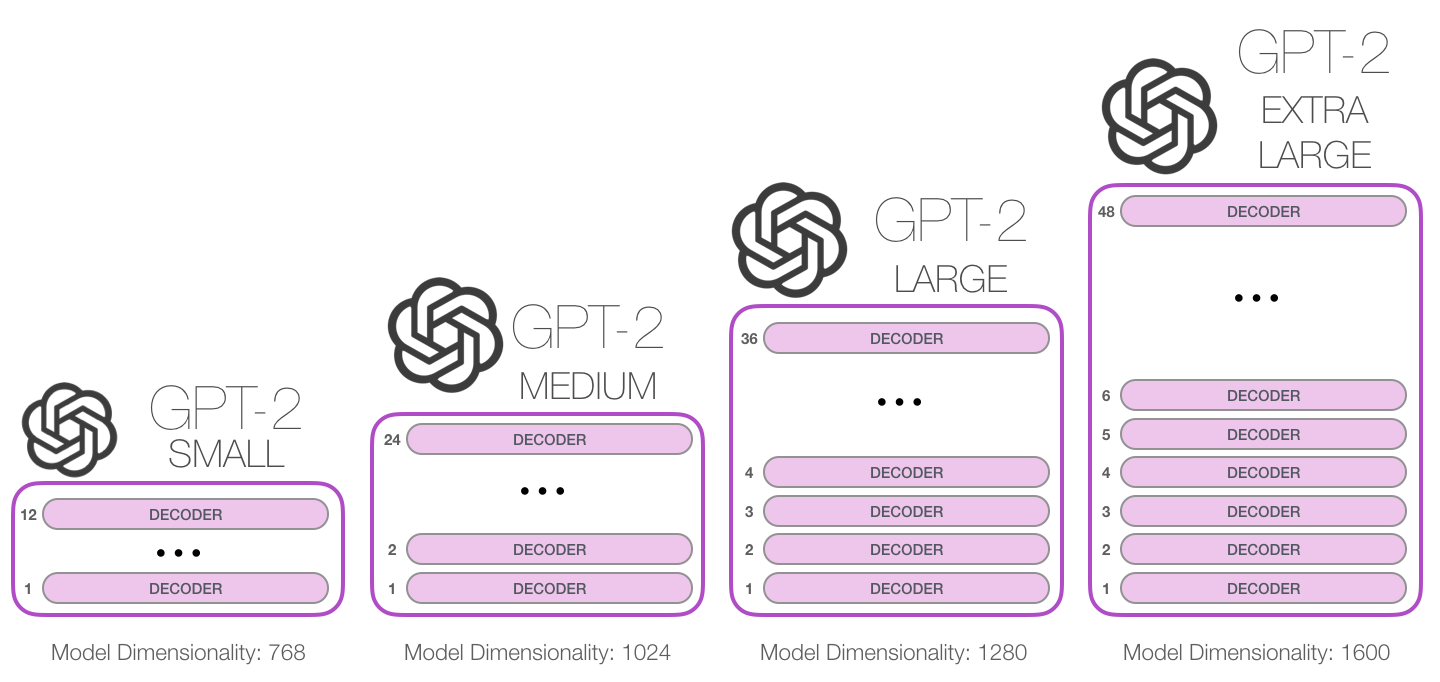
BERTとの1つの違い
ロボット工学の第一法則ロボットは人間を傷つけたり、不作為によって人間に危害を加えたりしてはなりません。
GPT-2 は、トランス デコーダ ブロックを使用して構築されています。一方、BERT は、Transformer エンコーダ ブロックを使用します。次のセクションで違いを調べます。ただし、2 つの主な違いの 1 つは、GPT2 が従来の言語モデルと同様に、一度に 1 つのトークンを出力することです。たとえば、よく訓練された GPT-2 にロボット工学の第一法則を暗唱するよう促してみましょう。
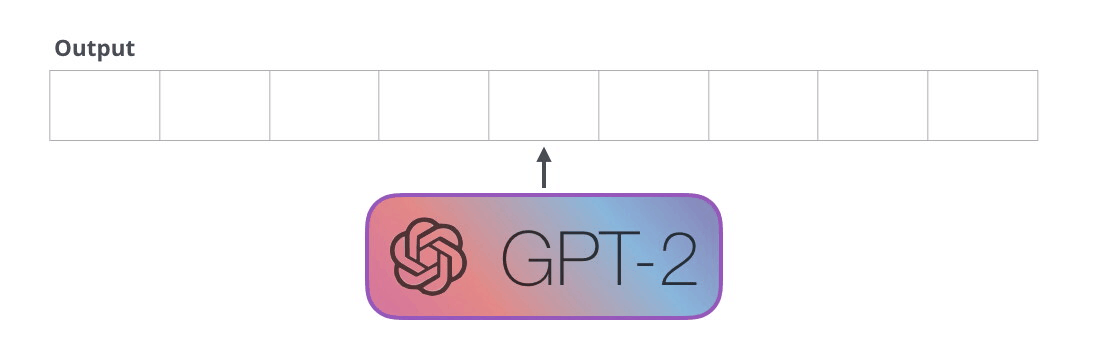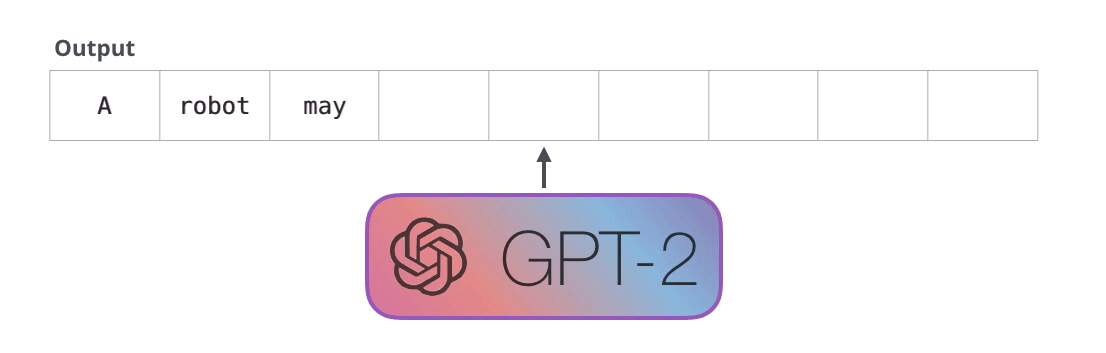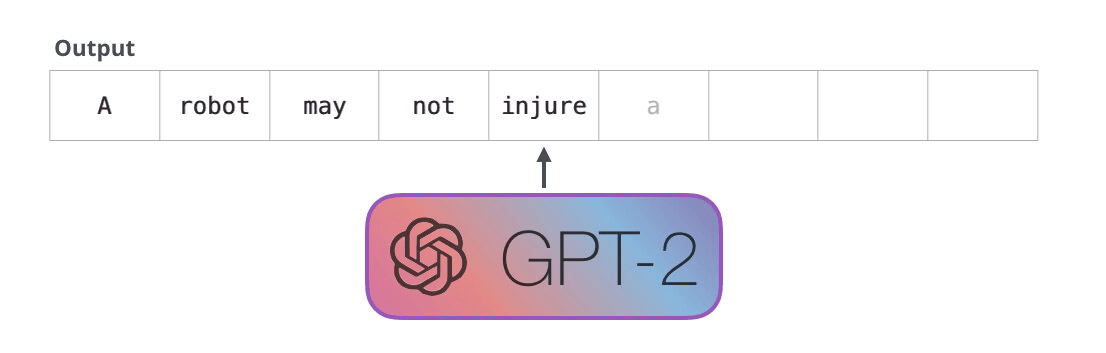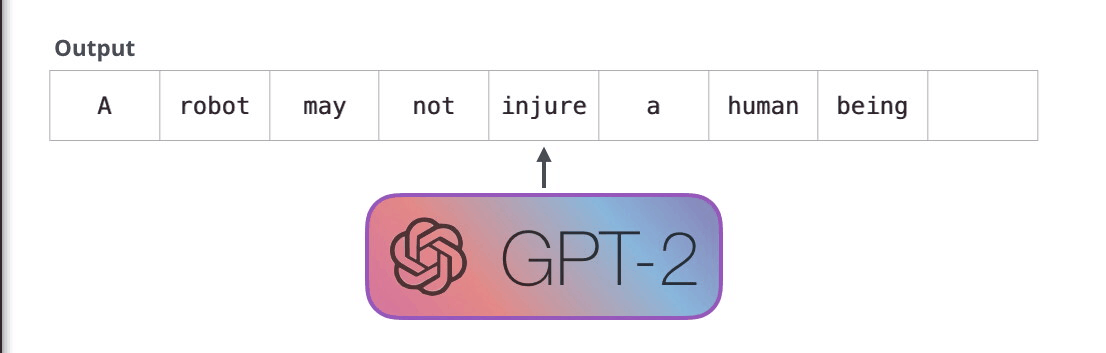
これらのモデルが実際に機能する方法は、各トークンが生成された後、そのトークンが一連の入力に追加されることです。そして、その新しいシーケンスは、次のステップでモデルへの入力になります。これが「自己回帰」という考え方です。これは、 RNN を不当に効果的なものにしたアイデアの 1 つです。
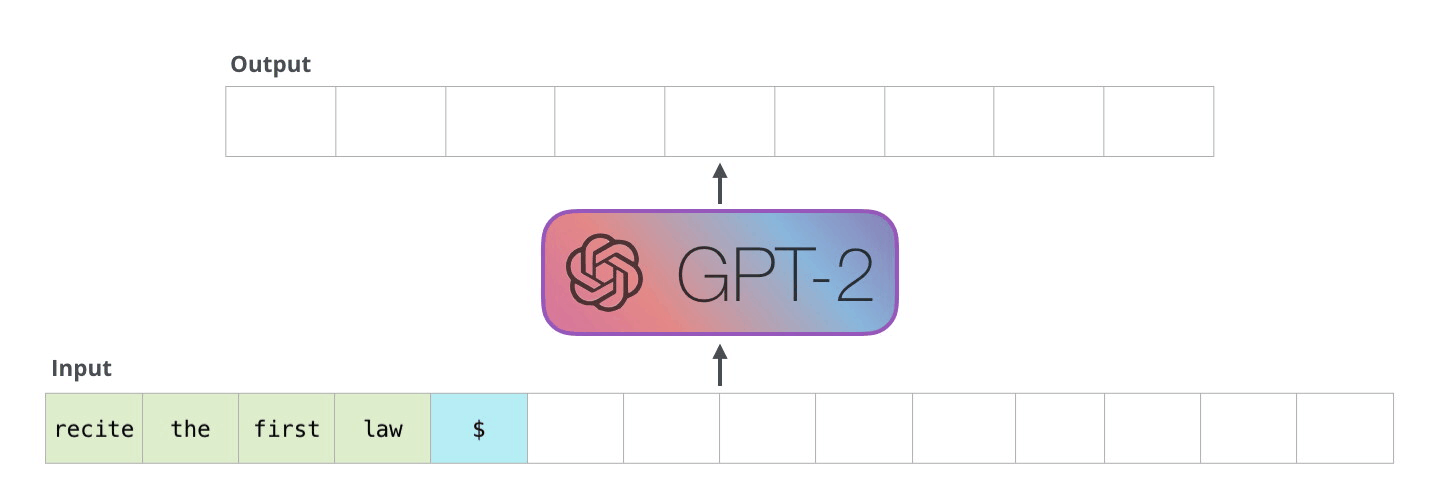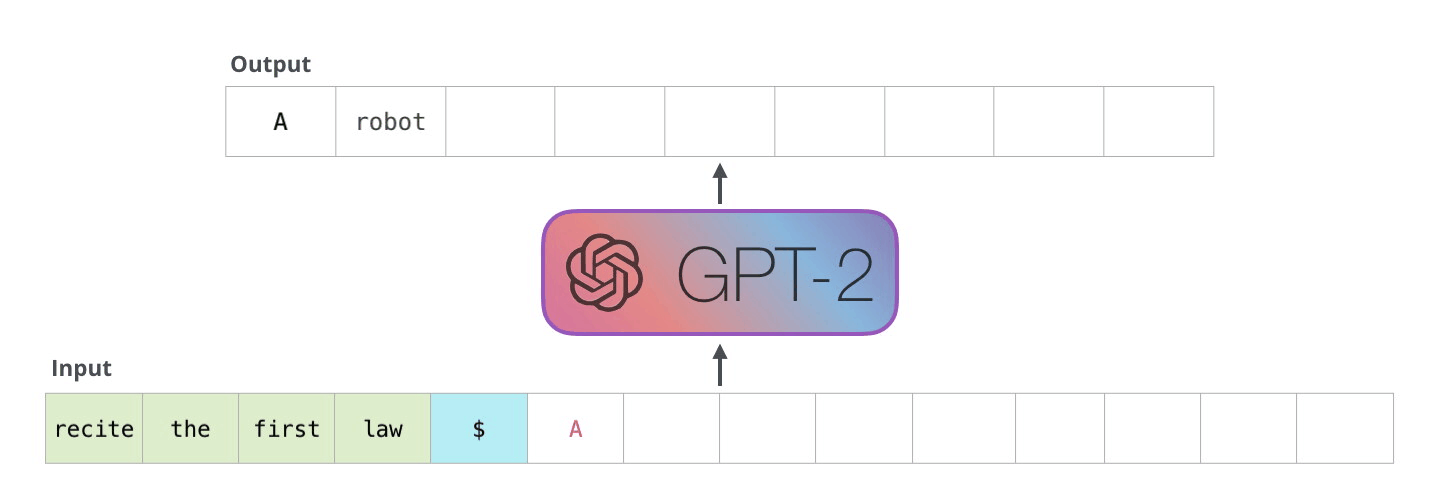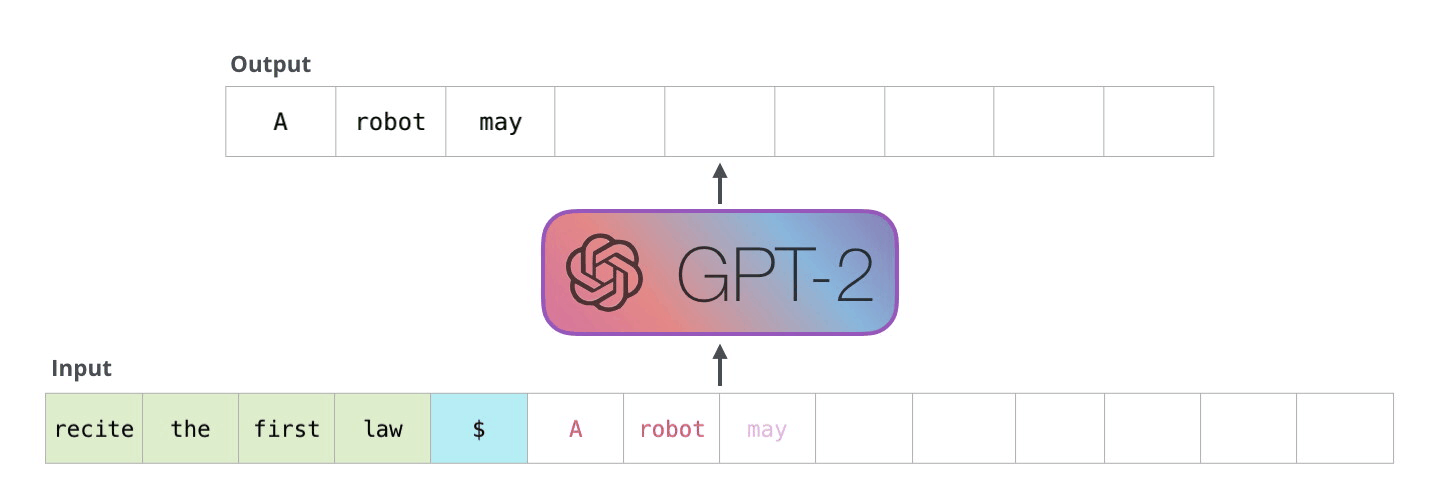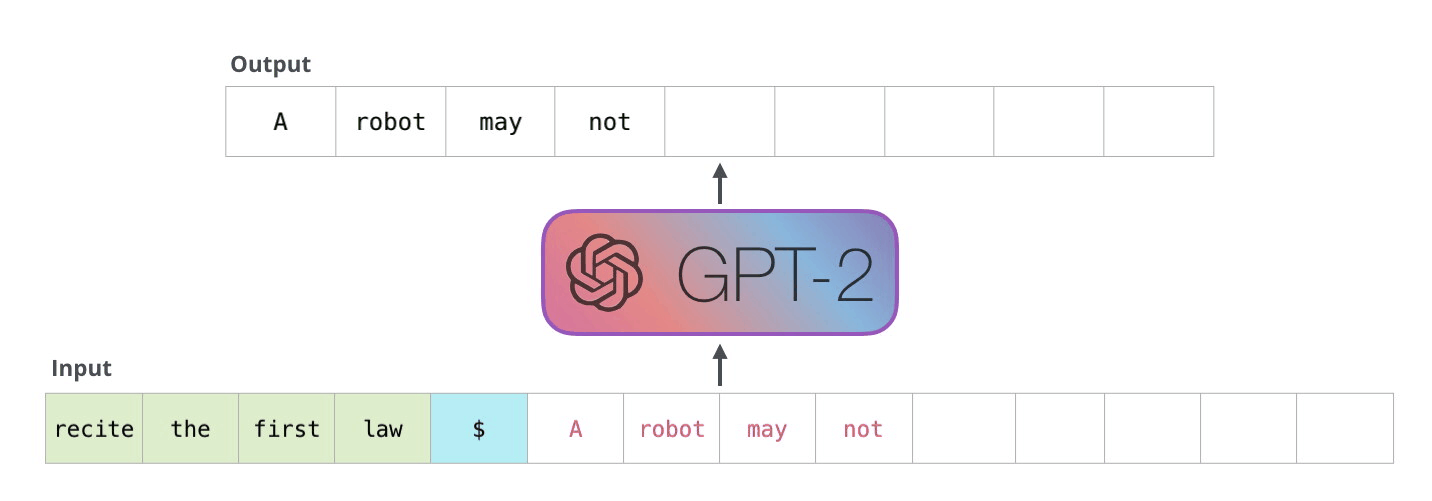
GPT2、および TransformerXL や XLNet などのいくつかの新しいモデルは、本質的に自己回帰的です。BERTはそうではありません。それはトレードオフです。自己回帰を失うことで、BERT は、より良い結果を得るために、単語の両側にコンテキストを組み込む機能を獲得しました。XLNet は、両側のコンテキストを組み込む別の方法を見つけながら、自己回帰を復活させます。
Transformer ブロックの進化
Transformerに関する最初の論文では、次の 2 種類の Transformer ブロックが導入されました。
エンコーダーブロック
最初はエンコーダ ブロックです。
![]()
オリジナルのトランスペーパーのエンコーダ ブロックは、特定の最大シーケンス長 (たとえば 512 トークン) まで入力を受け取ることができます。入力シーケンスがこの制限より短くても問題ありません。シーケンスの残りをパディングするだけです。
デコーダーブロック
2 つ目は、エンコーダー ブロックとはアーキテクチャが少し異なるデコーダー ブロックです。これは、エンコーダーからの特定のセグメントに注意を向けるためのレイヤーです。
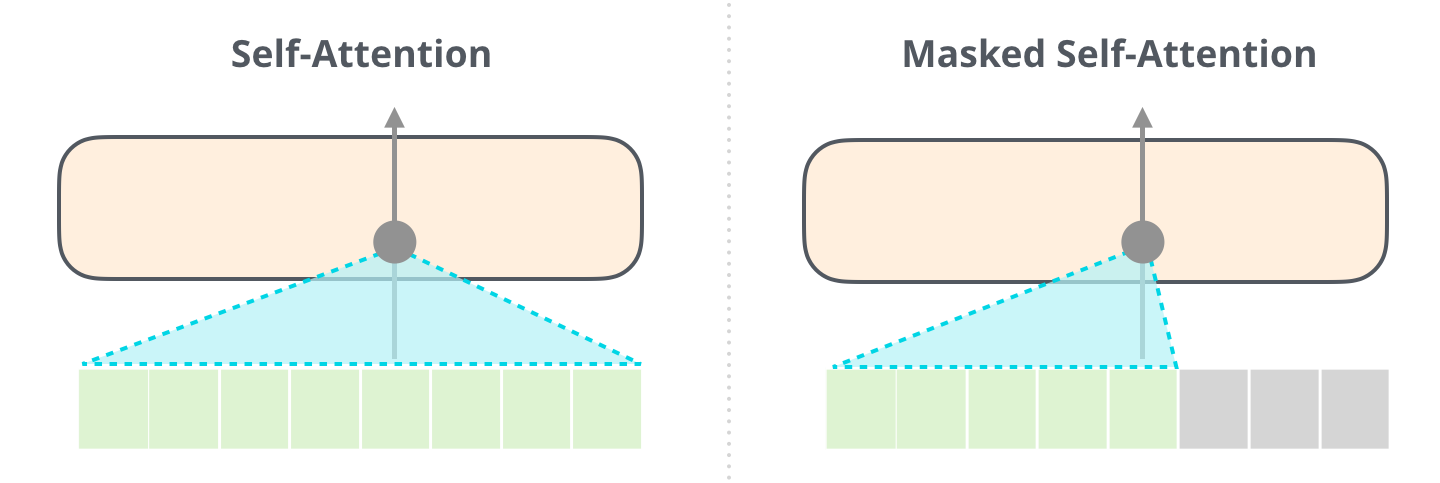
ここでの自己注意レイヤーの重要な違いの 1 つは、将来のトークンをマスクすることです。BERT のように単語を [マスク] に変更するのではなく、自己注意の計算に干渉して、トークンの右側にあるトークンからの情報をブロックします。計算中の位置。
たとえば、位置 #4 のパスを強調表示すると、現在および前のトークンにのみ参加できることがわかります。
自己注意 (BERT が使用するもの) とマスクされた自己注意 (GPT-2 が使用するもの) の違いを明確にすることが重要です。通常のセルフ・アテンション・ブロックでは、位置がその右側のトークンでピークに達することができます。マスクされた自己注意は、それが起こらないようにします。
デコーダーのみのブロック
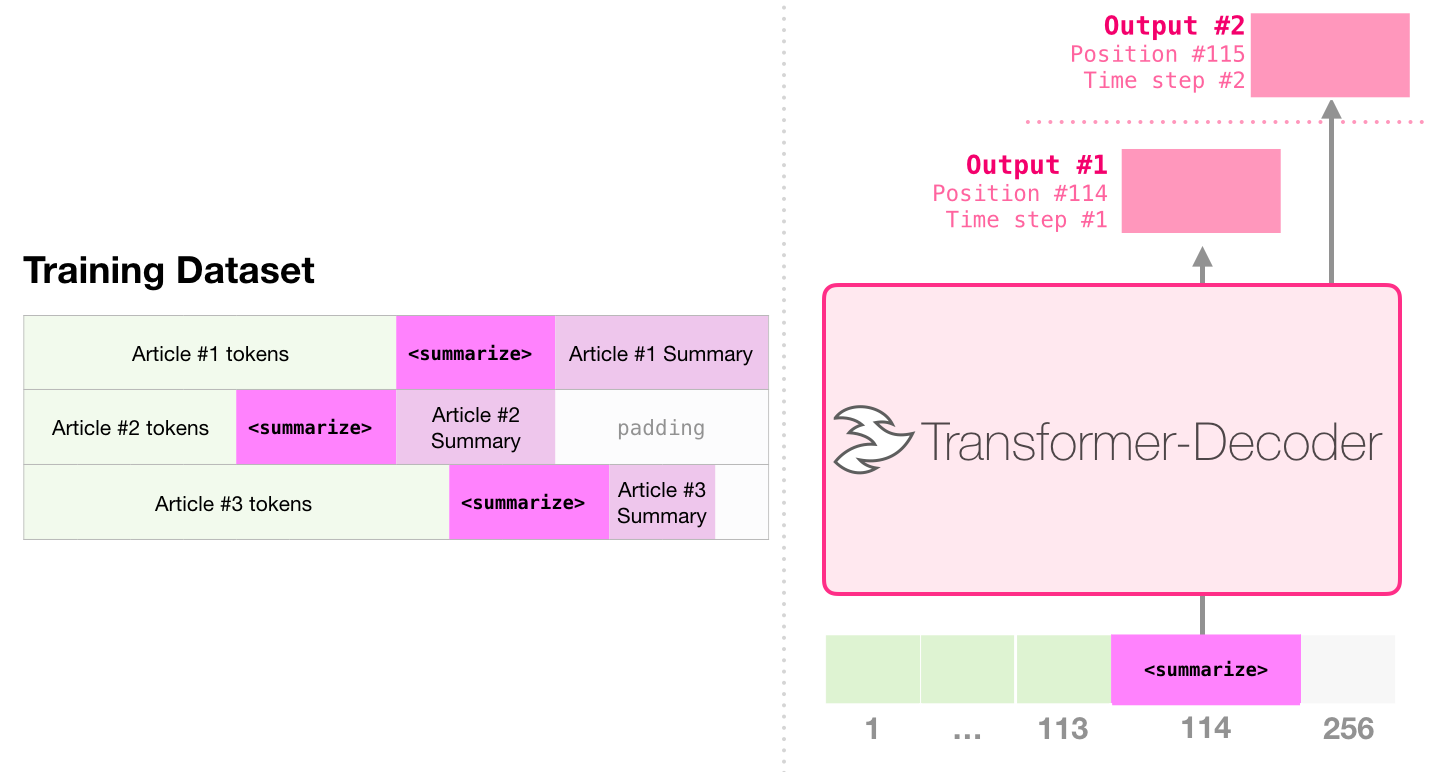
元の論文に続いて、長いシーケンスの要約によるウィキペディアの生成では、言語モデリングを実行できる変換ブロックの別の配置が提案されました。このモデルは Transformer エンコーダーを捨てました。そのため、このモデルを「Transformer-Decoder」と呼びましょう。この初期の変換器ベースの言語モデルは、次の 6 つの変換器デコーダ ブロックのスタックで構成されていました。
![]()
デコーダーブロックは同じです。最初のものを拡大したので、自己注意レイヤーがマスクされたバリアントであることがわかります。モデルが特定のセグメントで最大 4,000 トークンに対応できるようになったことに注意してください。元のトランスフォーマーの 512 から大幅にアップグレードされています。
これらのブロックは、第 2 のセルフアテンション レイヤーを削除したことを除いて、元のデコーダー ブロックと非常によく似ていました。同様のアーキテクチャがCharacter-Level Language Modeling with Deeper Self-Attention で調査され、一度に 1 文字を予測する言語モデルが作成されました。
OpenAI GPT-2 モデルは、これらのデコーダのみのブロックを使用します。
脳外科の短期集中コース: GPT-2 の内部を見る
中をのぞいてみるとわかるよ 言葉が脳裏に深く刻み込まれている。雷が燃える、すぐに燃える、言葉のナイフが私を狂わせる、狂っている。〜セキセイインコ
トレーニング済みの GPT-2 を手術台に置き、それがどのように機能するかを見てみましょう。
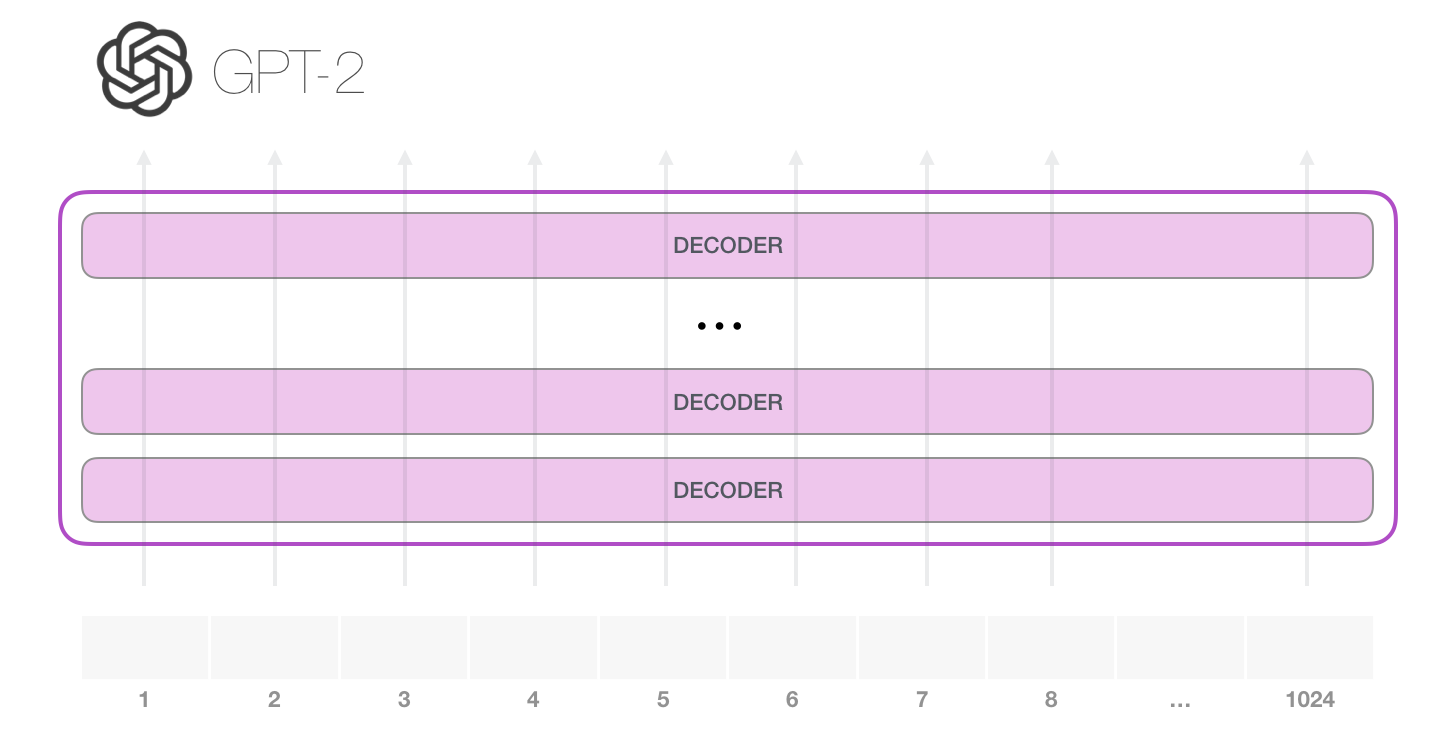
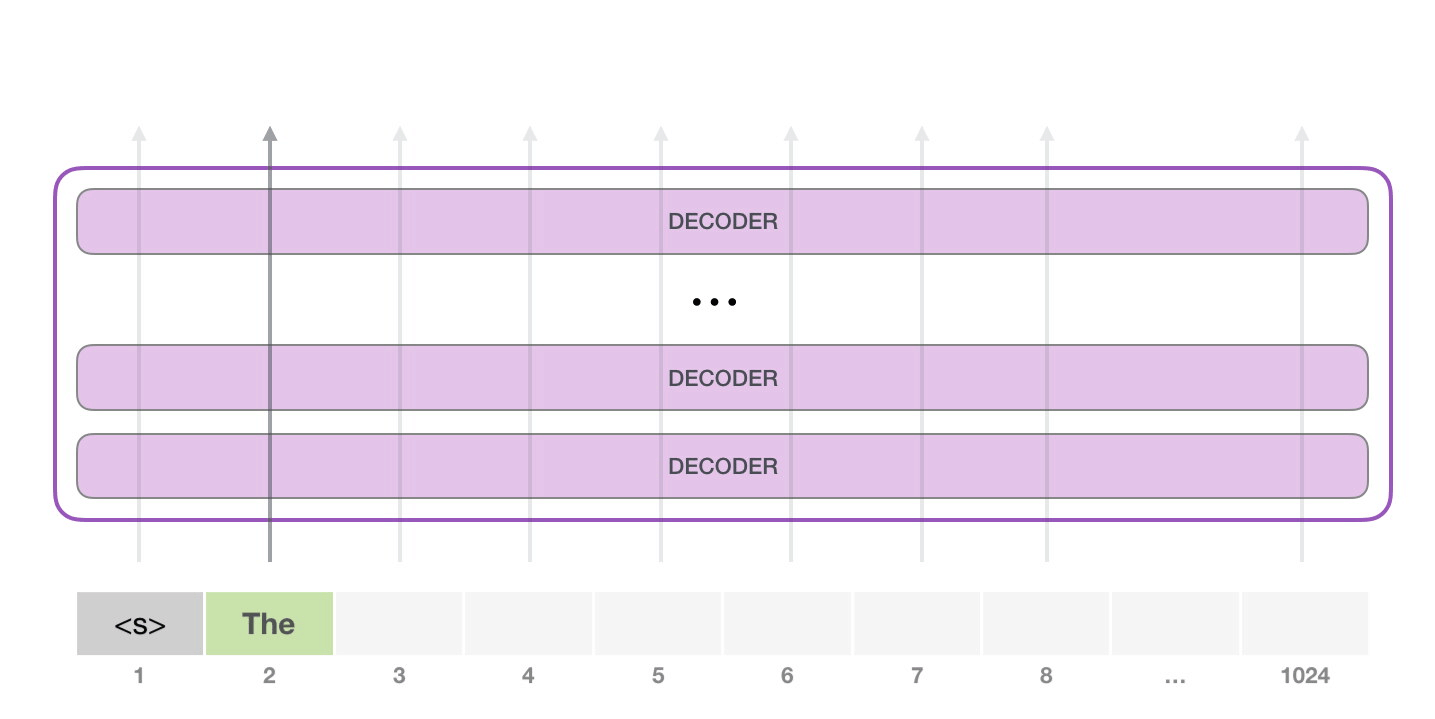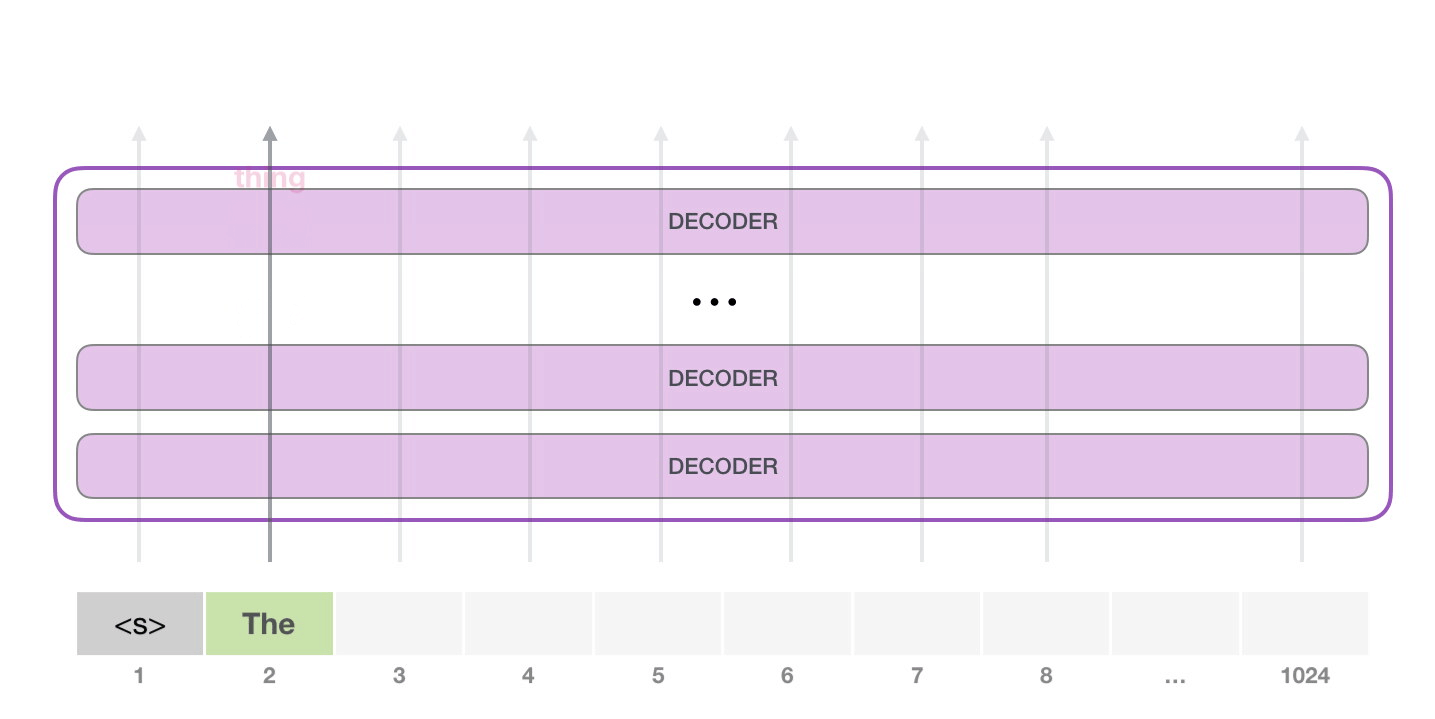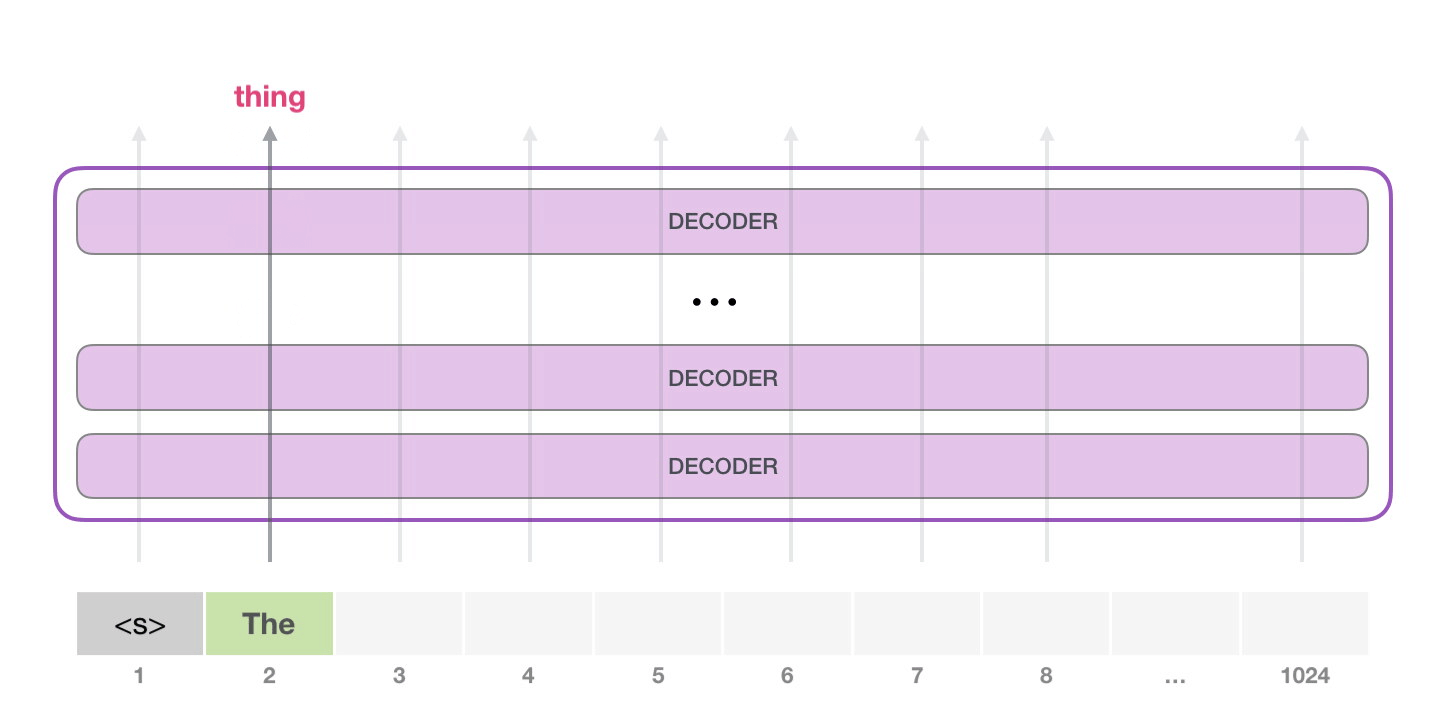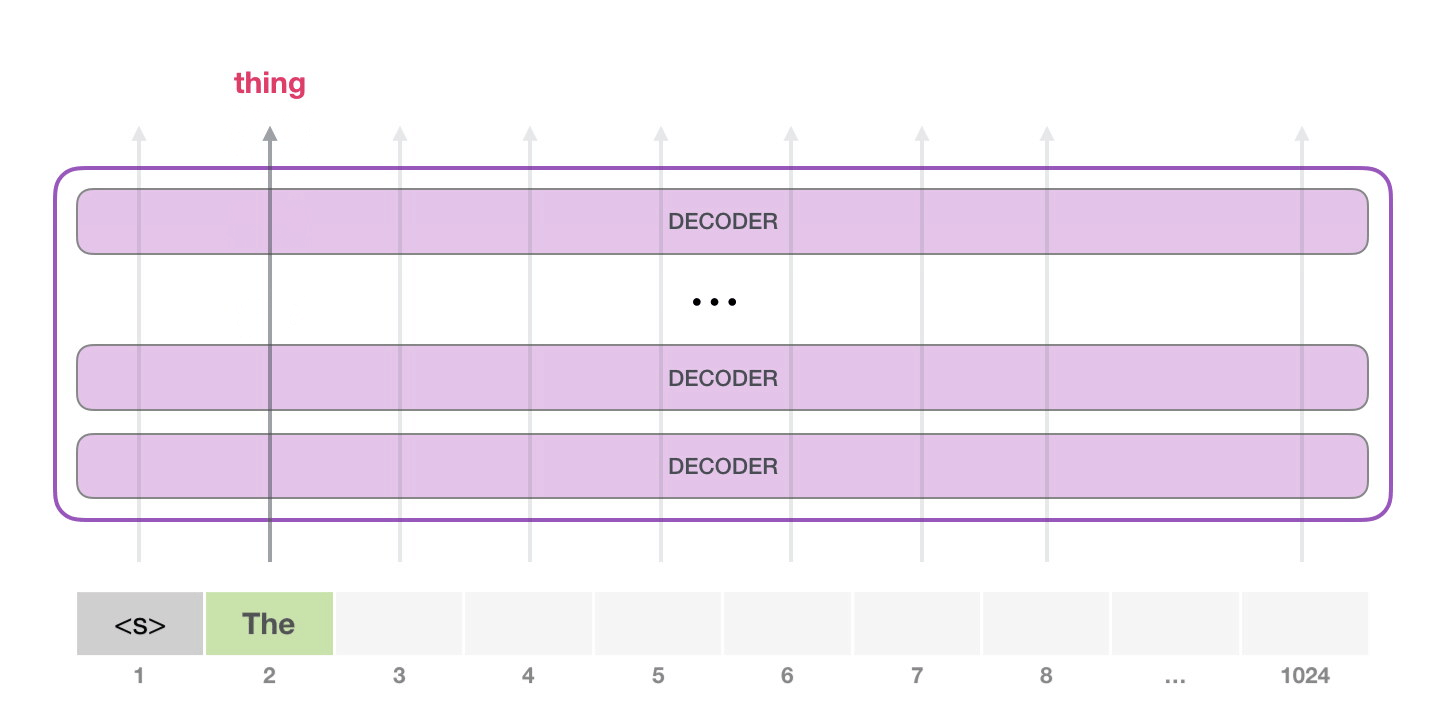
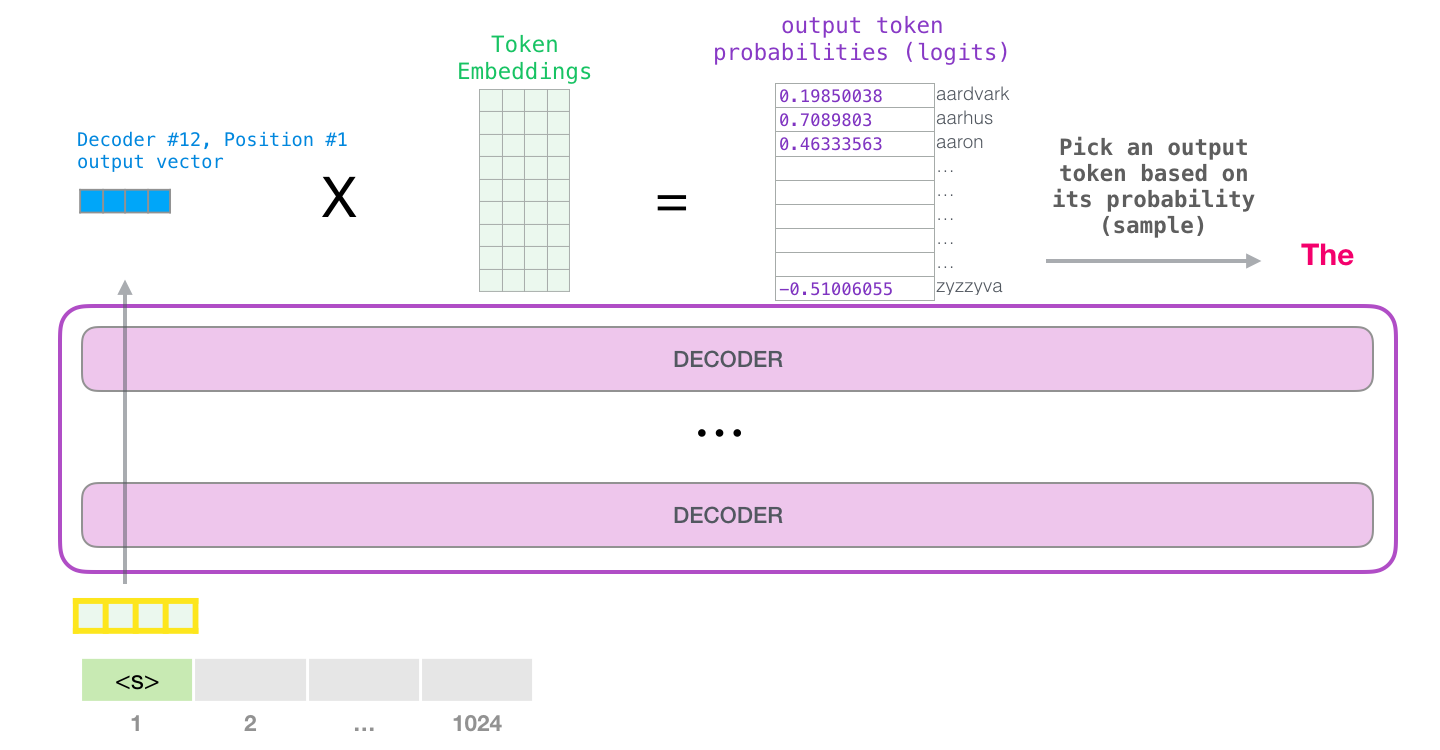
GPT-2 は 1024 個のトークンを処理できます。各トークンは、独自のパスに沿ってすべてのデコーダ ブロックを通過します。
トレーニング済みの GPT-2 を実行する最も簡単な方法は、GPT-2 を単独で実行できるようにすることです (技術的には、無条件のサンプルの生成と呼ばれます)。別の方法として、特定のトピックについて話させるようにプロンプトを与えることもできます (対話型の条件付きサンプルの生成とも呼ばれます)。サンプル)。とりとめのないケースでは、単純に開始トークンを渡して、単語の生成を開始させることができます (トレーニングされたモデルは開始トークンとして使用します。代わりに<|endoftext|>呼び出しましょう)。<s>
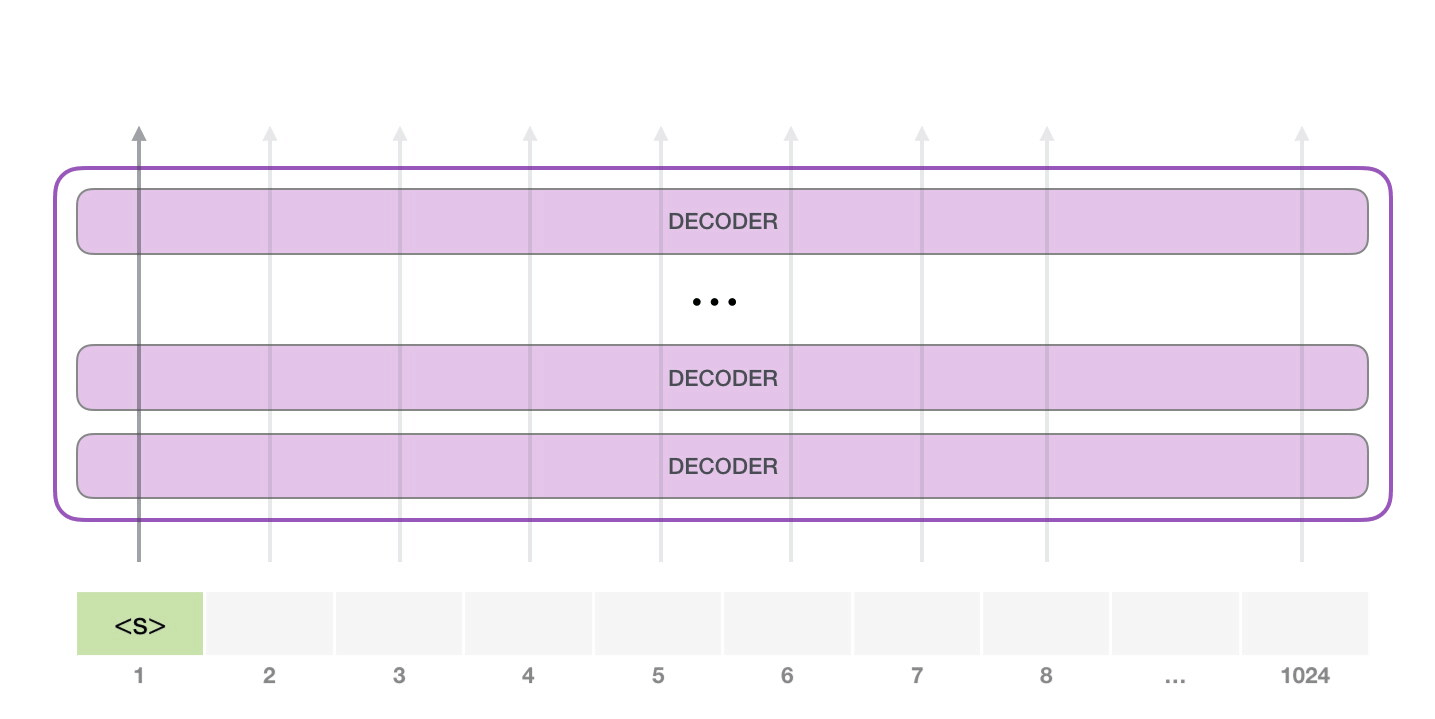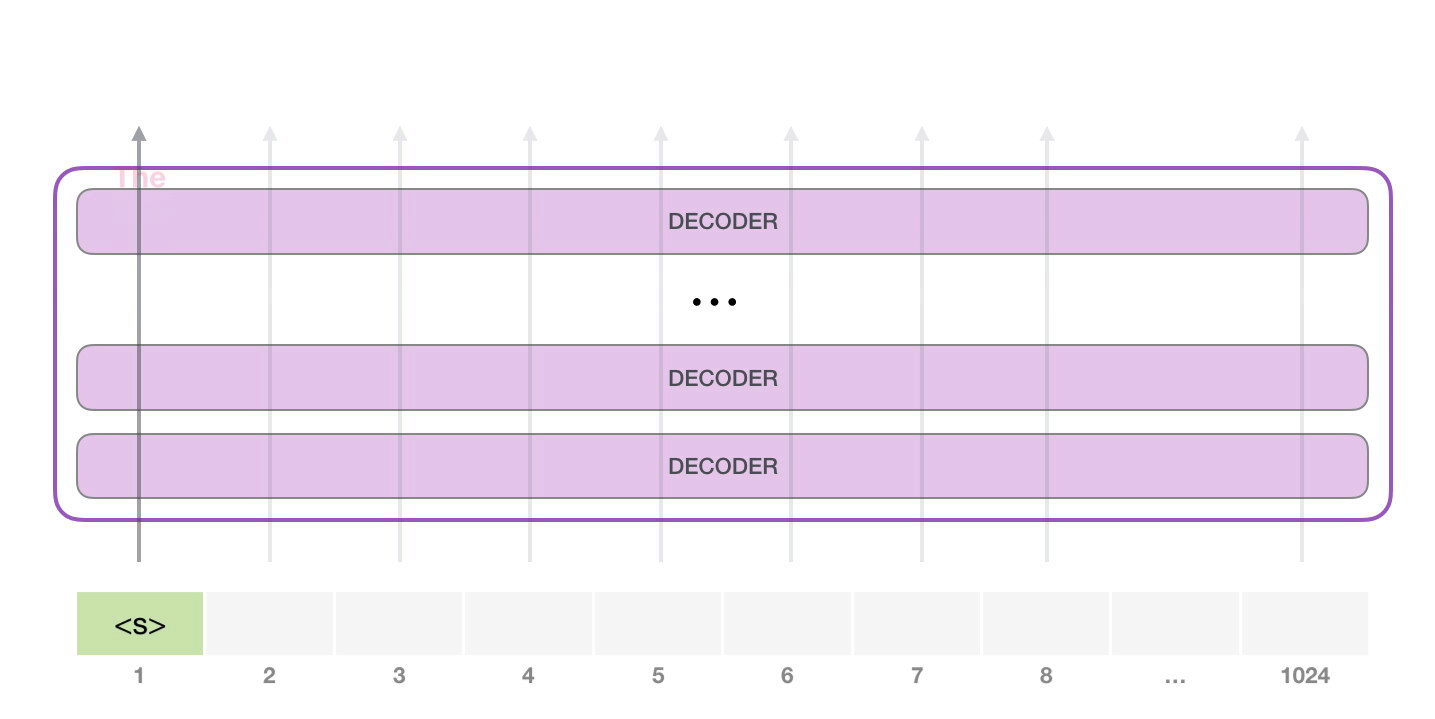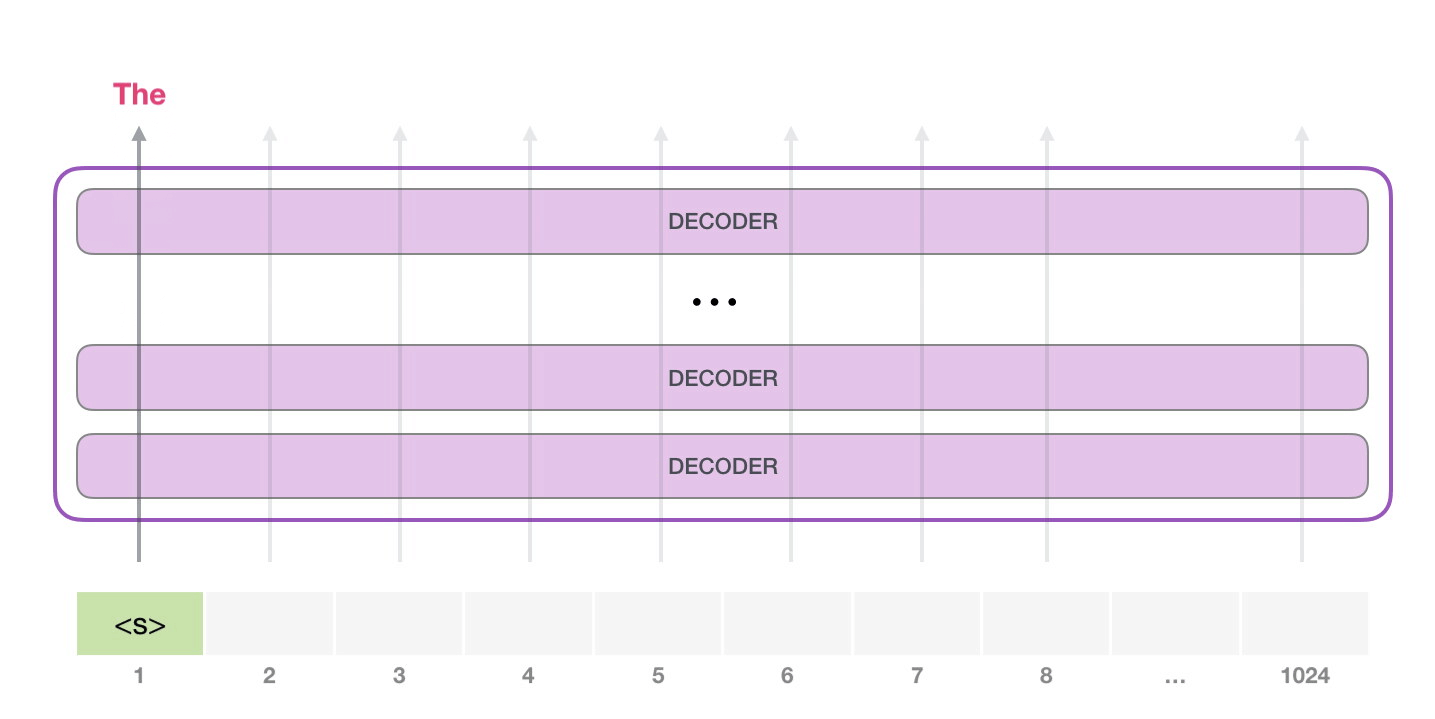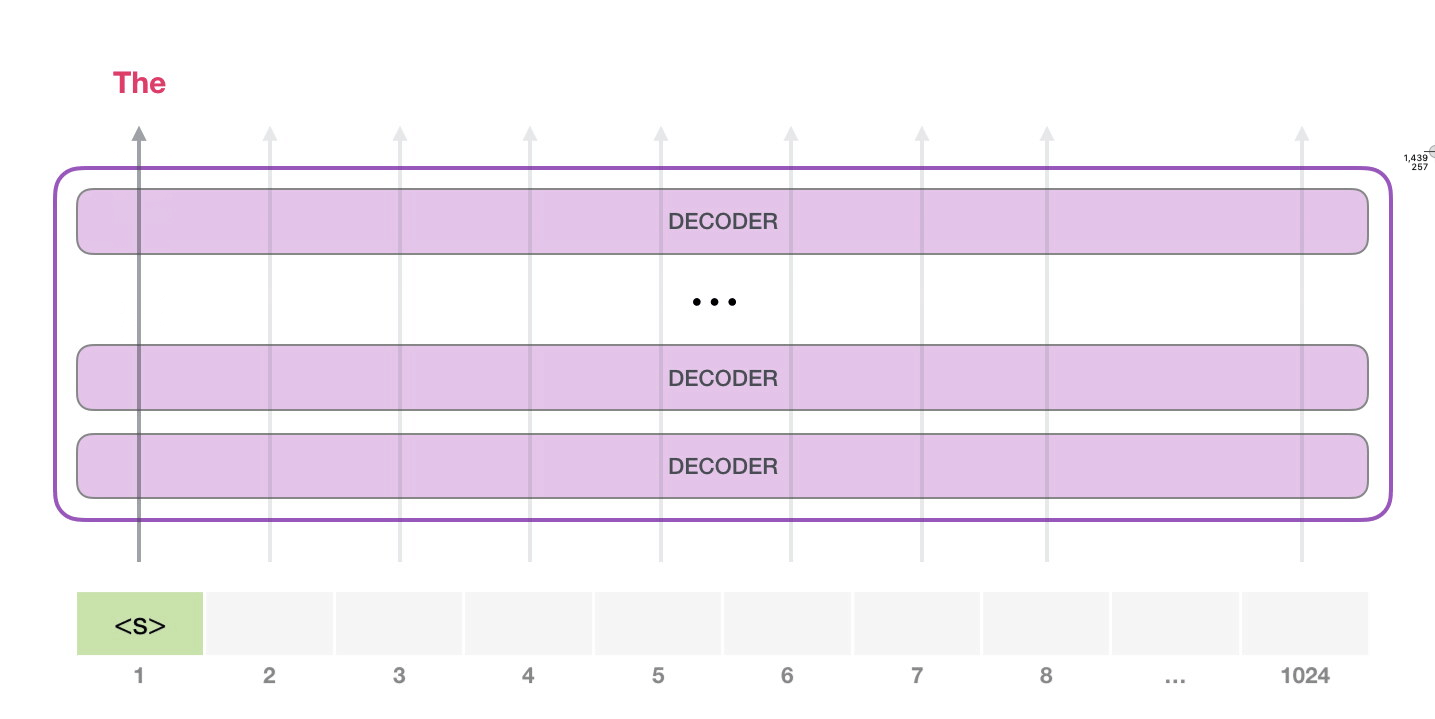
モデルには入力トークンが 1 つしかないため、そのパスが唯一のアクティブなトークンになります。トークンはすべてのレイヤーで連続して処理され、そのパスに沿ってベクトルが生成されます。そのベクトルは、モデルの語彙 (モデルが知っているすべての単語、GPT-2 の場合は 50,000 単語) に対してスコア付けできます。この場合、確率が最も高いトークン「the」を選択しました。しかし、ご存じのように、キーボード アプリで提案された単語をクリックし続けると、2 番目または 3 番目の提案された単語をクリックすることが唯一の方法である反復ループに陥ることがあります。ここでも同じことが起こります。GPT-2 には top-k と呼ばれるパラメーターがあり、これを使用してモデルにトップ ワード以外のサンプリング ワードを考慮することができます (これは、トップ k = 1 の場合です)。
次のステップでは、最初のステップからの出力を入力シーケンスに追加し、モデルに次の予測を行わせます。
この計算でアクティブなのは 2 番目のパスだけであることに注意してください。GPT-2 の各レイヤーは、最初のトークンの独自の解釈を保持しており、2 番目のトークンの処理に使用します (これについては、自己注意に関する次のセクションで詳しく説明します)。GPT-2 は、2 番目のトークンに照らして最初のトークンを再解釈しません。
より深い内観
入力エンコーディング
モデルをより詳しく知るために、詳細を見てみましょう。まずはインプットから。前に説明した他の NLP モデルと同様に、モデルは埋め込み行列 (トレーニング済みモデルの一部として取得するコンポーネントの 1 つ) で入力単語の埋め込みを検索します。
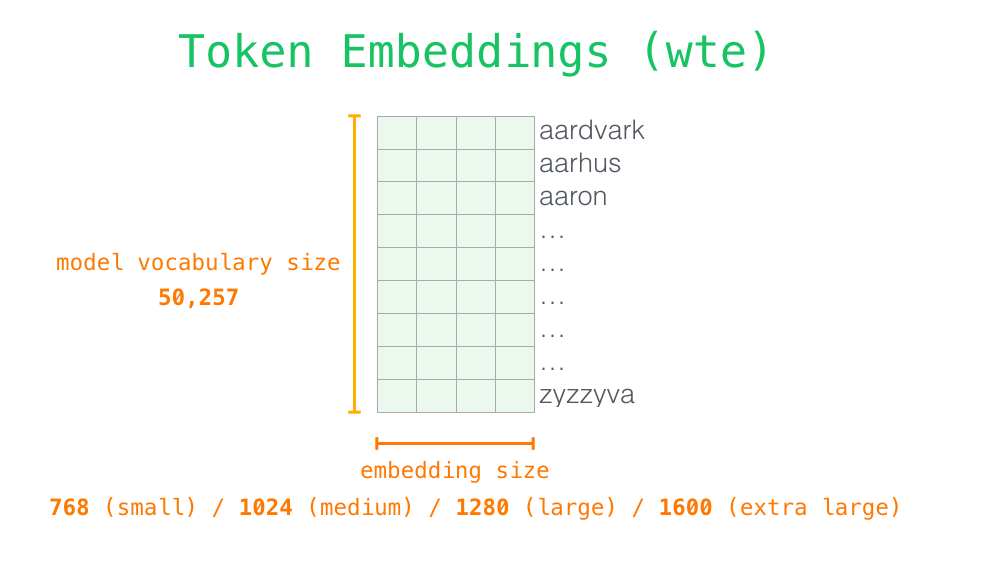
各行は単語の埋め込みです: 単語を表し、その意味の一部をキャプチャする数字のリストです。そのリストのサイズは、GPT2 モデルのサイズによって異なります。最小のモデルでは、単語/トークンあたり 768 の埋め込みサイズが使用されます。
<s>そのため、最初に、埋め込みマトリックスでの開始トークンの埋め込みを調べます。それをモデルの最初のブロックに渡す前に、位置エンコーディングを組み込む必要があります。これは、シーケンス内の単語の順序を変換ブロックに示す信号です。トレーニング済みモデルの一部は、入力内の 1024 の位置それぞれの位置エンコーディング ベクトルを含む行列です。
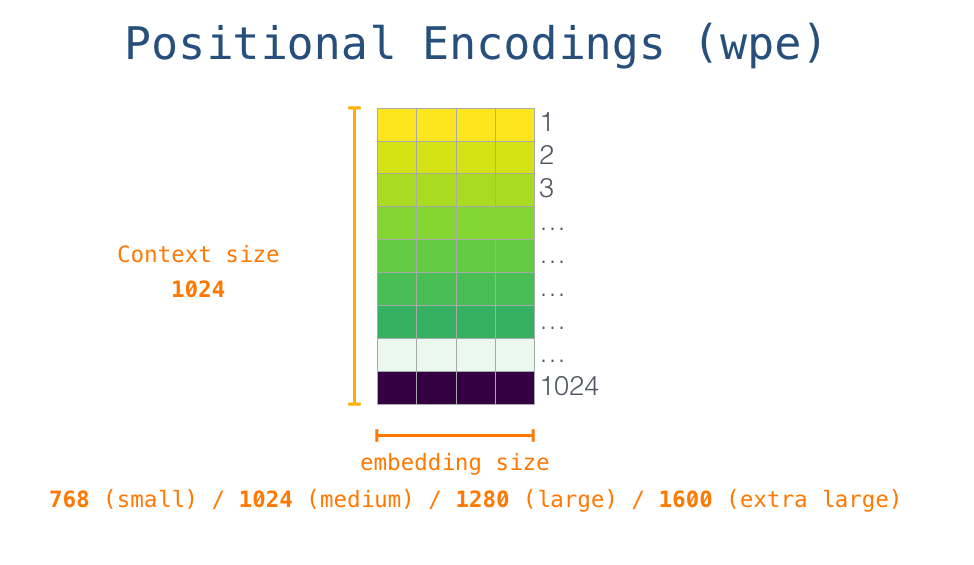
これで、入力単語が最初の変換ブロックに渡される前にどのように処理されるかについて説明しました。また、トレーニング済みの GPT-2 を構成する 2 つの重み行列もわかっています。

単語を最初の変換ブロックに送信するということは、その埋め込みを調べて、位置 #1 の位置エンコーディング ベクトルを加算することを意味します。
スタックを上る旅
最初のブロックは、最初にトークンを自己注意プロセスに渡し、次にニューラル ネットワーク レイヤーに渡すことで、トークンを処理できるようになりました。最初のトランスフォーマー ブロックがトークンを処理すると、その結果のベクターがスタックに送信され、次のブロックで処理されます。プロセスは各ブロックで同じですが、各ブロックには自己注意とニューラル ネットワーク サブレイヤーの両方で独自の重みがあります。
自己注意の要約
言語は文脈に大きく依存します。たとえば、次の第 2 法則を見てください。
ロボット工学の第 2 法則ロボットは、第 1 法則と矛盾する場合を除き、人間から与えられた命令に 従わなければなりません。
単語が他の単語を参照している文の 3 つの場所を強調表示しました。これらの単語が参照しているコンテキストを組み込むことなく、これらの単語を理解または処理する方法はありません。モデルがこの文を処理するとき、次のことを認識できなければなりません。
- それはロボットを指す
- そのような命令は、法律の最初の部分、すなわち「人間によって与えられた命令」を指します。
- 第一法は、第一法全体を指す
これが自己注意の働きです。これは、特定の単語を処理する (ニューラル ネットワークに渡す) 前に、特定の単語のコンテキストを説明する、関連する単語と関連する単語のモデルの理解を焼き付けます。これは、セグメント内の各単語の関連性にスコアを割り当て、それらのベクトル表現を合計することによって行われます。
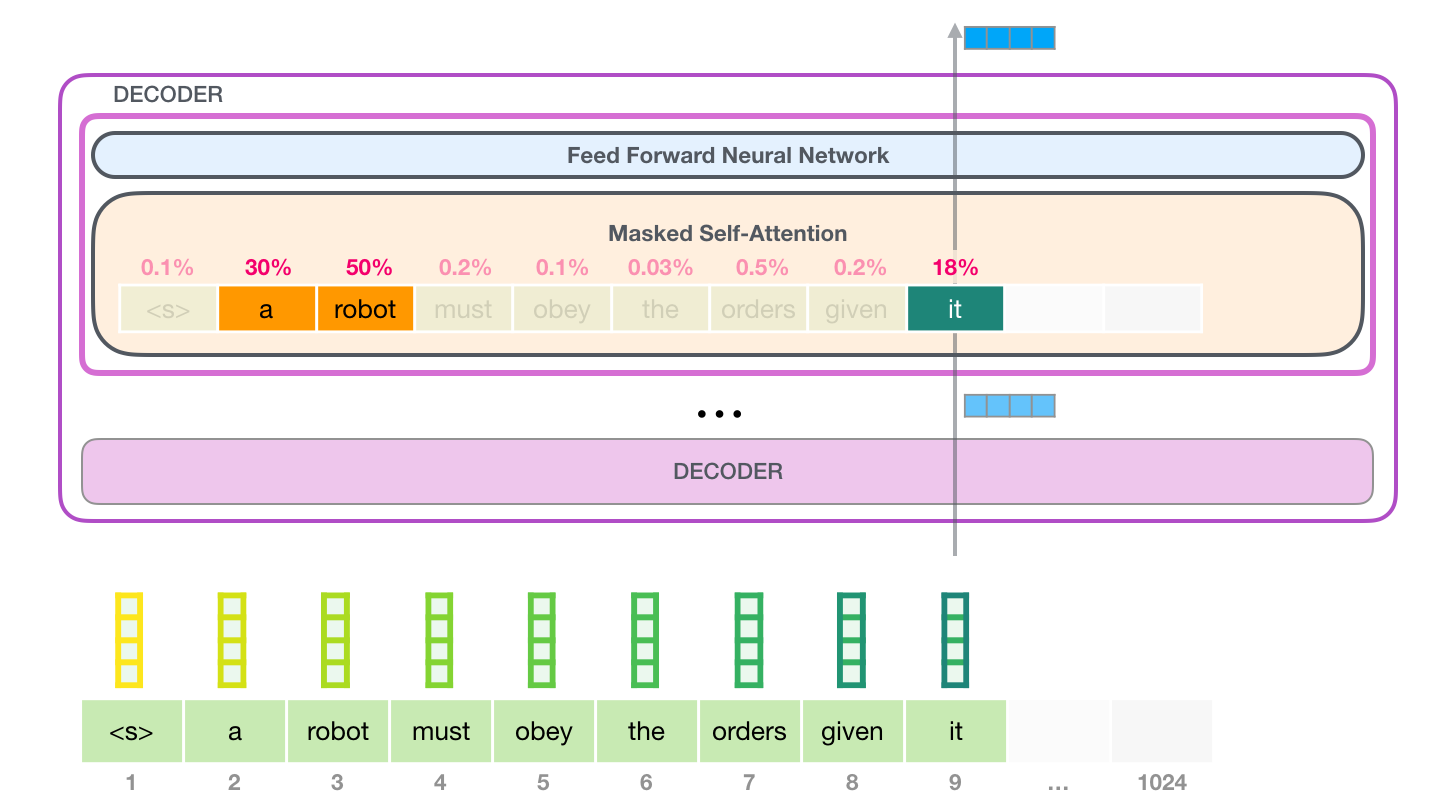
例として、一番上のブロックにあるこの自己注意層は、単語「it」を処理するときに「ロボット」に注意を払っています。ニューラル ネットワークに渡すベクトルは、3 つの単語のそれぞれのベクトルの合計にスコアを掛けたものです。
自己注意プロセス
自己注意は、セグメント内の各トークンのパスに沿って処理されます。重要なコンポーネントは、次の 3 つのベクトルです。
- クエリ: クエリは、(キーを使用して) 他のすべての単語に対してスコアを付けるために使用される現在の単語の表現です。現在処理中のトークンのクエリのみを考慮します。
- Key : キー ベクトルは、セグメント内のすべての単語のラベルのようなものです。これらは、関連する単語を検索する際に照合するものです。
- 値: 値ベクトルは実際の単語表現です。各単語の関連性をスコアリングすると、現在の単語を表すために加算された値になります。
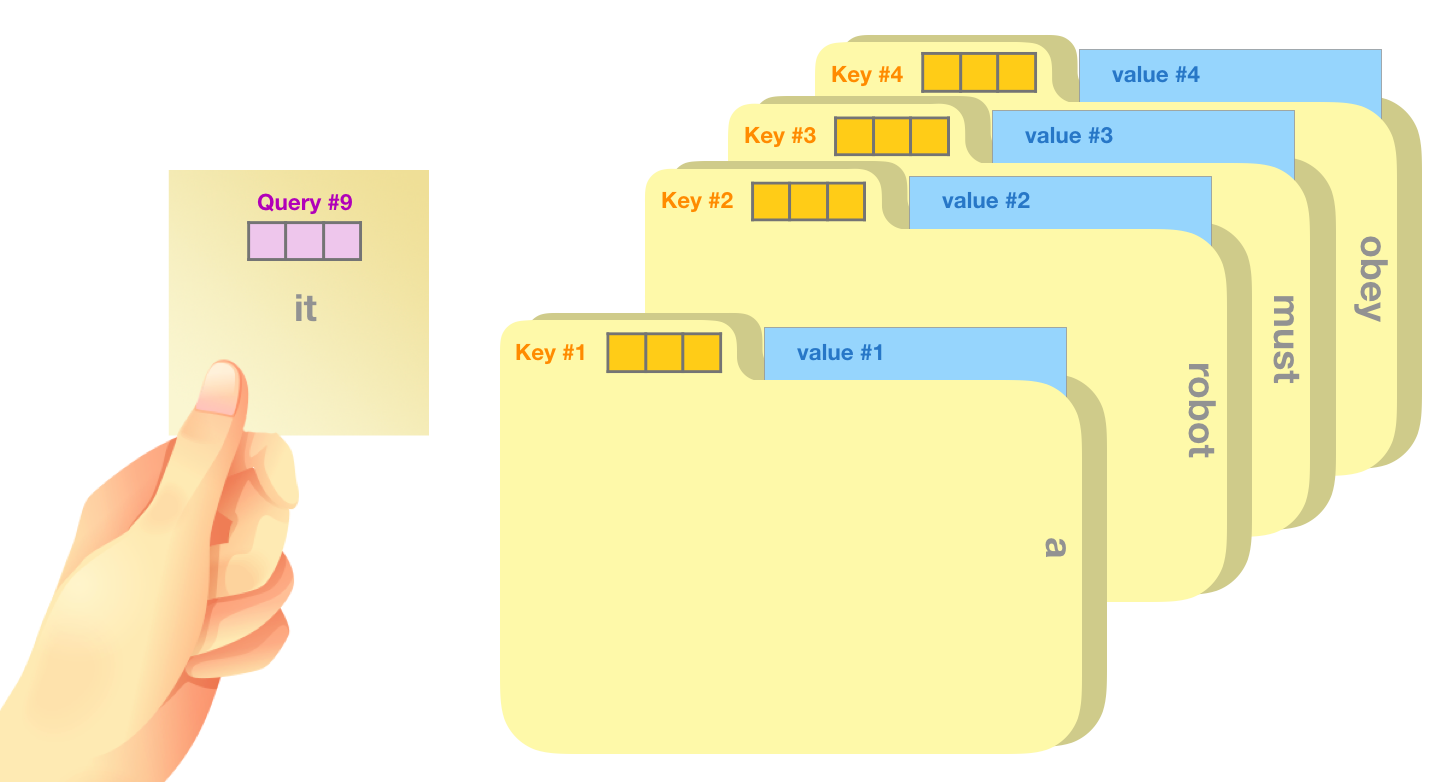
大まかな例えは、ファイリング キャビネットを検索するようなものです。クエリは、調査しているトピックの付箋のようなものです。キーは、キャビネット内のフォルダーのラベルのようなものです。タグを付箋と一致させると、そのフォルダーの内容が取り出されます。これらの内容は値ベクトルです。1 つの値だけを探しているのではなく、フォルダーのブレンドからの値のブレンドを探している場合を除きます。
クエリ ベクトルを各キー ベクトルで乗算すると、各フォルダーのスコアが生成されます (技術的には、内積とソフトマックスの順)。
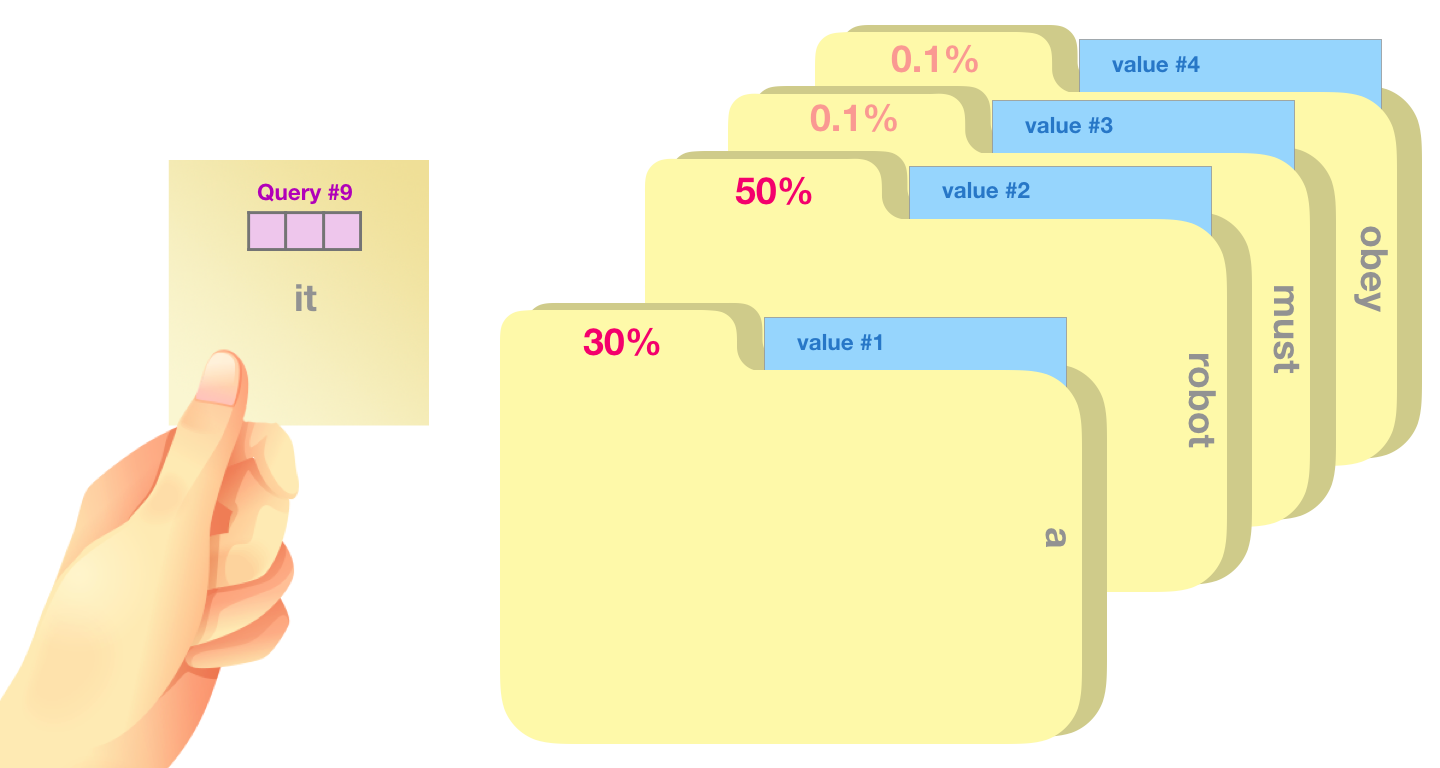
各値にそのスコアを掛けて合計すると、自己注意の結果が得られます。
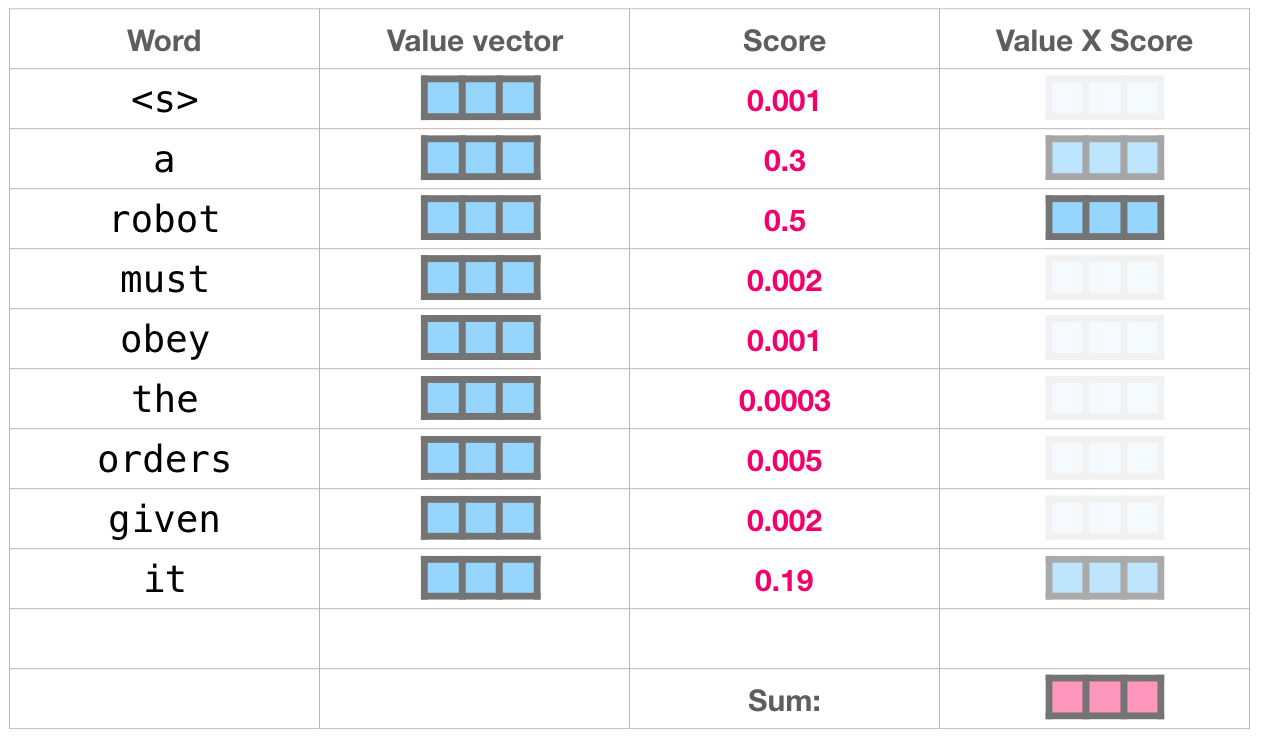
値ベクトルのこの加重ブレンドにより、単語 に 50%、単語robotに 30%、単語aに 19%の「注意」を払ったベクトルが得られitます。この記事の後半で、自己注意について詳しく説明します。しかし、最初に、モデルの出力に向けてスタックを上って行きましょう。
モデル出力
モデルの一番上のブロックが出力ベクトル (独自のニューラル ネットワークによる自己注意の結果) を生成すると、モデルはそのベクトルに埋め込み行列を乗算します。
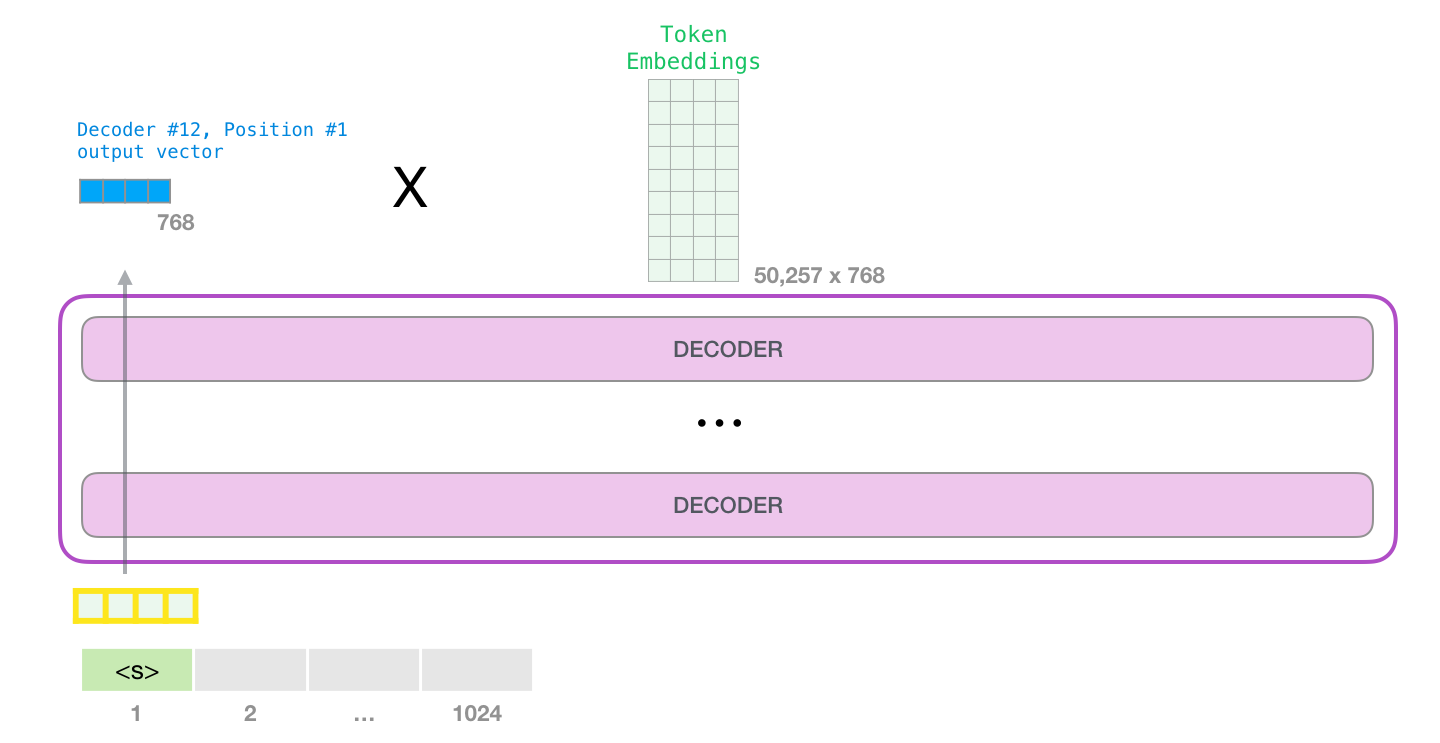
埋め込み行列の各行は、モデルの語彙への単語の埋め込みに対応していることを思い出してください。この乗算の結果は、モデルの語彙の各単語のスコアとして解釈されます。
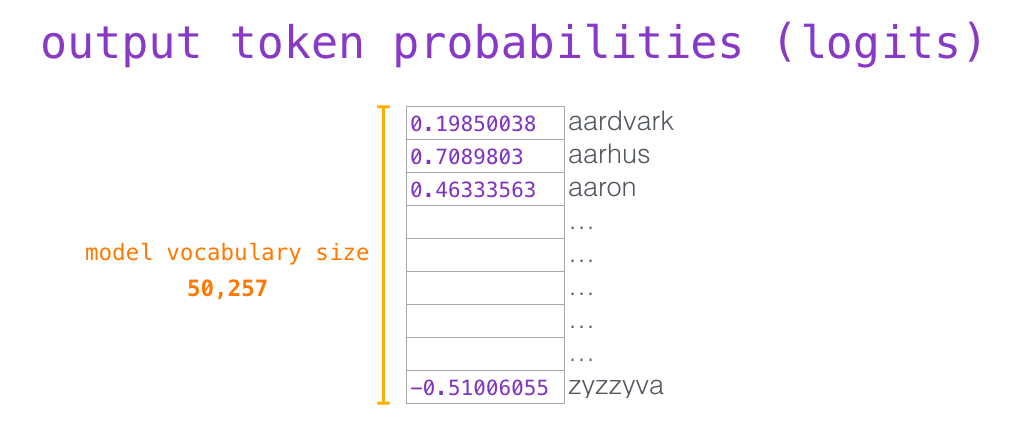
最も高いスコア (top_k = 1) を持つトークンを選択するだけです。ただし、モデルが他の単語も考慮すると、より良い結果が得られます。したがって、より良い戦略は、その単語を選択する確率としてスコアを使用して、リスト全体から単語をサンプリングすることです (したがって、スコアが高い単語ほど、選択される可能性が高くなります)。妥協点は、top_k を 40 に設定し、モデルに最高スコアの 40 語を考慮させることです。
これで、モデルは反復を完了し、単一の単語を出力しました。モデルは、コンテキスト全体が生成されるまで (1024 トークン)、またはシーケンスの終わりのトークンが生成されるまで反復を続けます。
パート 1 の終了: GPT-2、ご列席の皆様
そして、それがあります。GPT2 の仕組みの概要。自己注意層の内部で何が起こっているかを正確に知りたい場合は、次のボーナス セクションを参照してください。後のトランスフォーマー モデルの説明をより簡単に調べて説明できるようにするために、自己注意を説明するためのより視覚的な言語を導入するために作成しました (TransformerXL と XLNet を見てください)。
この投稿では、いくつかの単純化しすぎていることに注意してください。
- 「単語」と「トークン」を同じ意味で使用しました。しかし実際には、GPT2 はバイト ペア エンコーディングを使用して、そのボキャブラリでトークンを作成します。これは、通常、トークンが単語の一部であることを意味します。
- 示した例では、推論/評価モードで GPT2 を実行しています。そのため、一度に 1 つの単語しか処理していません。トレーニング時に、モデルはより長いテキスト シーケンスに対してトレーニングされ、一度に複数のトークンを処理します。また、トレーニング時に、モデルは、評価で使用されるバッチ サイズよりも大きなバッチ サイズ (512) を処理します。
- 画像内のスペースをより適切に管理するために、自由にベクトルを回転/転置しました。実装時には、より正確にする必要があります。
- トランスフォーマーはレイヤーの正規化を大量に使用しますが、これは非常に重要です。イラスト付きトランスフォーマーでこれらのいくつかを指摘しましたが、この投稿では自己注意に焦点を当てています.
- ベクトルを表すために、より多くのボックスを表示する必要がある場合があります。それらを「ズームイン」と示します。例えば:
パート #2: 説明された自己注意#
投稿の前半で、単語を処理しているレイヤーに自己注意が適用されていることを示すために、この画像を示しましたit。

このセクションでは、その方法の詳細を見ていきます。個々の単語に何が起こるかを理解しようとする方法でそれを見ることに注意してください。そのため、多くの単一ベクトルを表示します。実際の実装は、巨大な行列を乗算することによって行われます。しかし、ここでは単語レベルで何が起こるかという直感に焦点を当てたいと思います。
Self-Attention (マスキングなし)
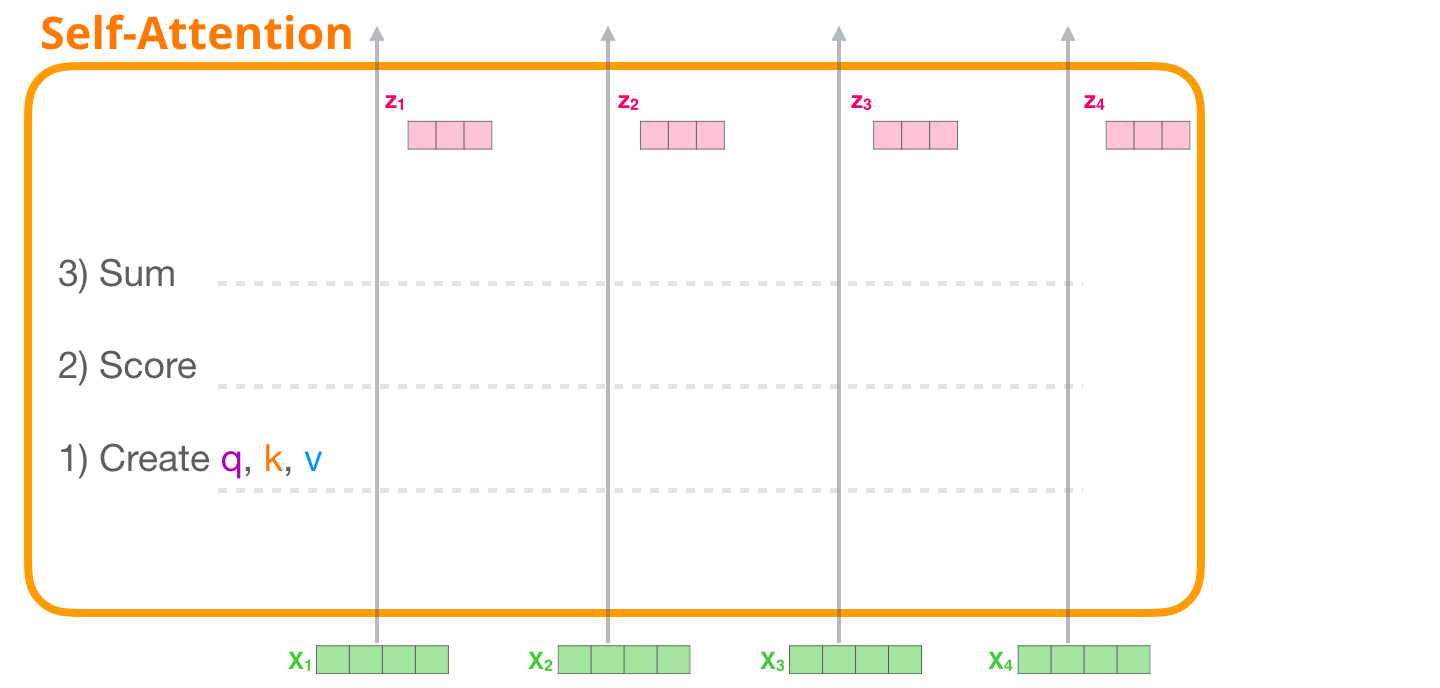
エンコーダ ブロックで計算される元の自己注意を見てみましょう。一度に 4 つのトークンしか処理できないおもちゃの変圧器ブロックを見てみましょう。
自己注意は、次の 3 つの主な手順で適用されます。
- 各パスのクエリ、キー、および値のベクトルを作成します。
- 入力トークンごとに、そのクエリ ベクトルを使用して、他のすべてのキー ベクトルに対してスコアを付けます。
- 値ベクトルに関連するスコアを掛けた後、値ベクトルを合計します。
1- クエリ、キー、および値のベクトルを作成する
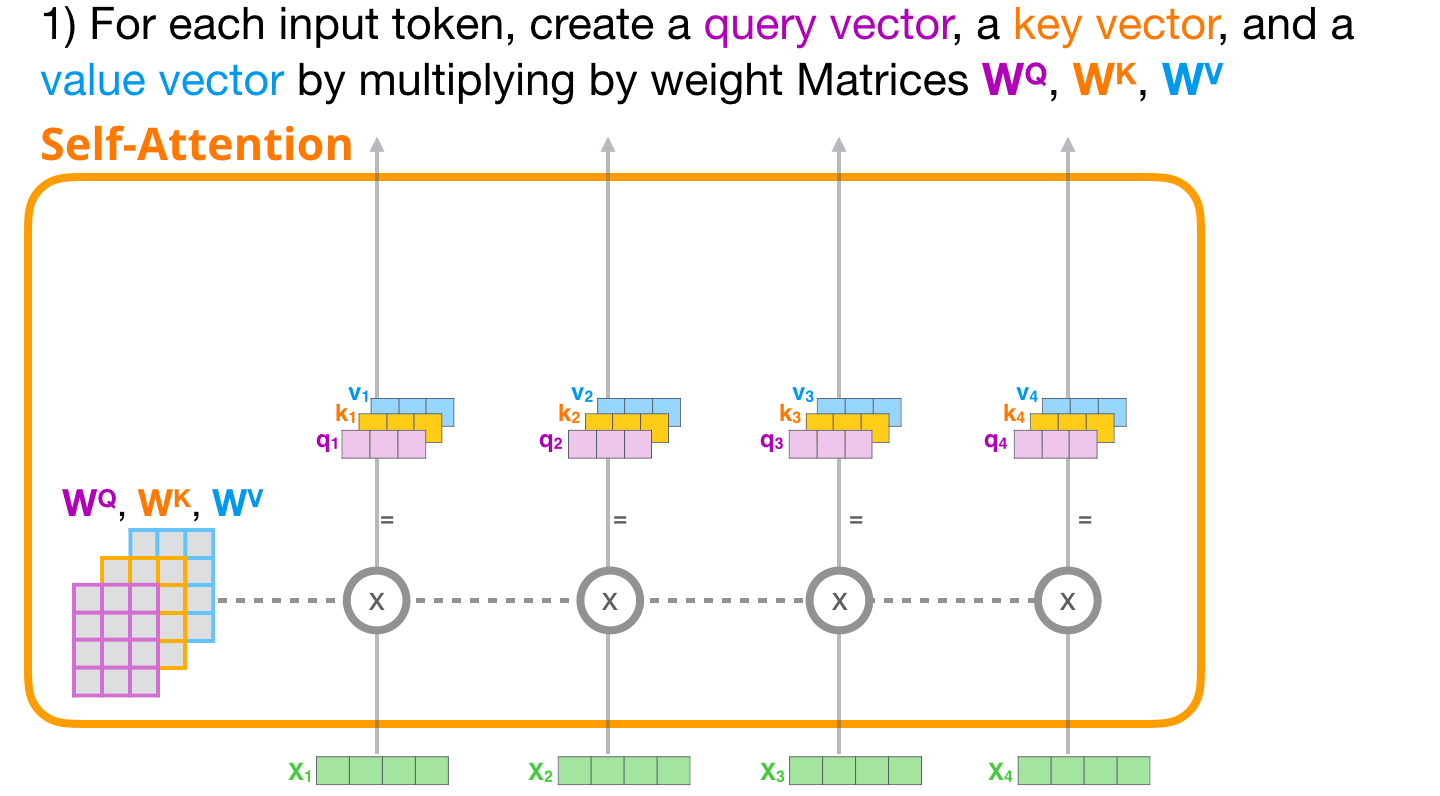
最初のパスに注目しましょう。そのクエリを取得し、すべてのキーと比較します。これにより、各キーのスコアが生成されます。セルフアテンションの最初のステップは、各トークン パスの 3 つのベクトルを計算することです (ここでは、アテンション ヘッドは無視します)。
2-スコア
ベクトルを取得したので、ステップ 2 でのみクエリとキー ベクトルを使用します。最初のトークンに注目しているので、そのクエリに他のすべてのキー ベクトルを掛けて、4 つのトークンそれぞれのスコアを求めます。
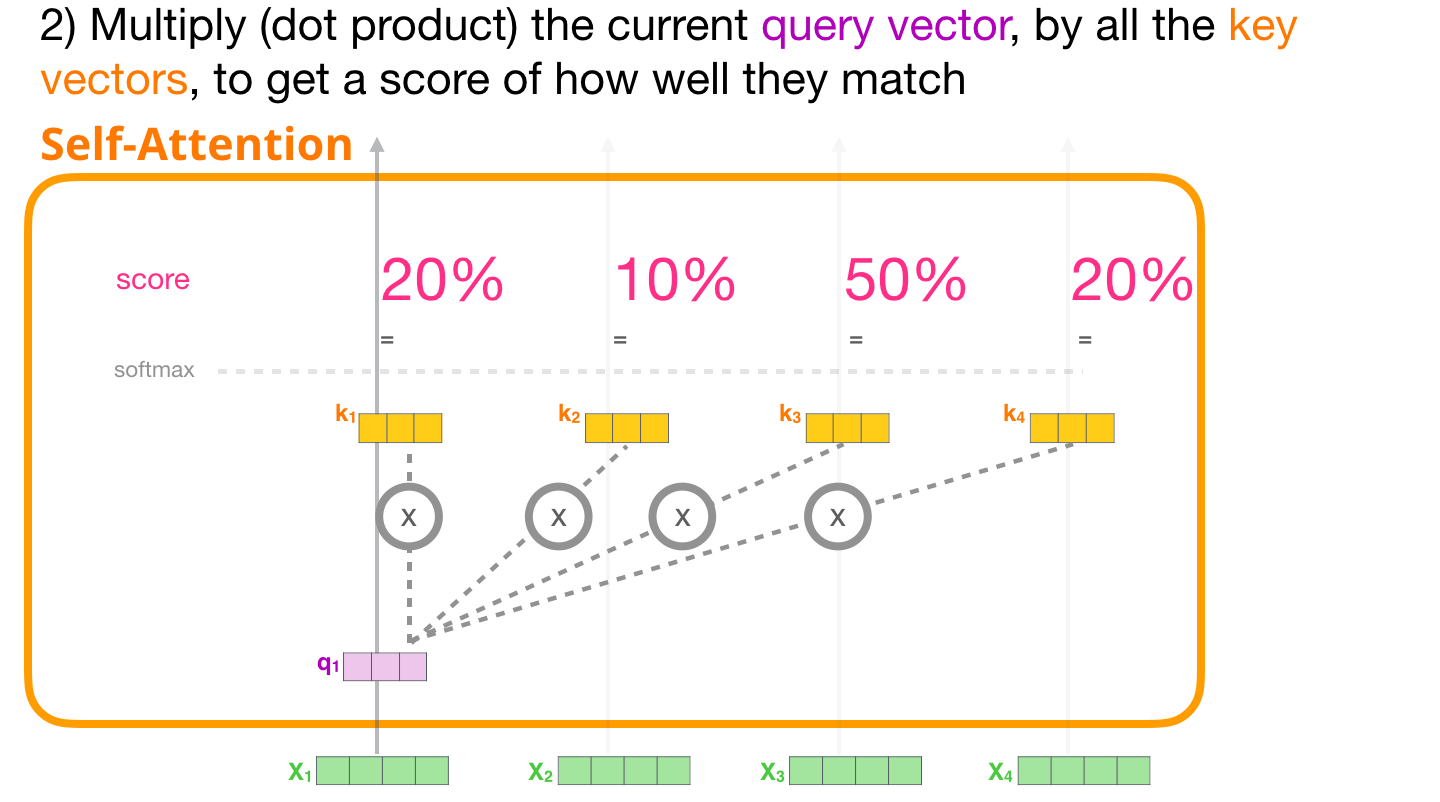
3-合計
これで、スコアに値ベクトルを掛けることができます。スコアの高い値は、それらを合計した後の結果のベクトルの大部分を構成します。
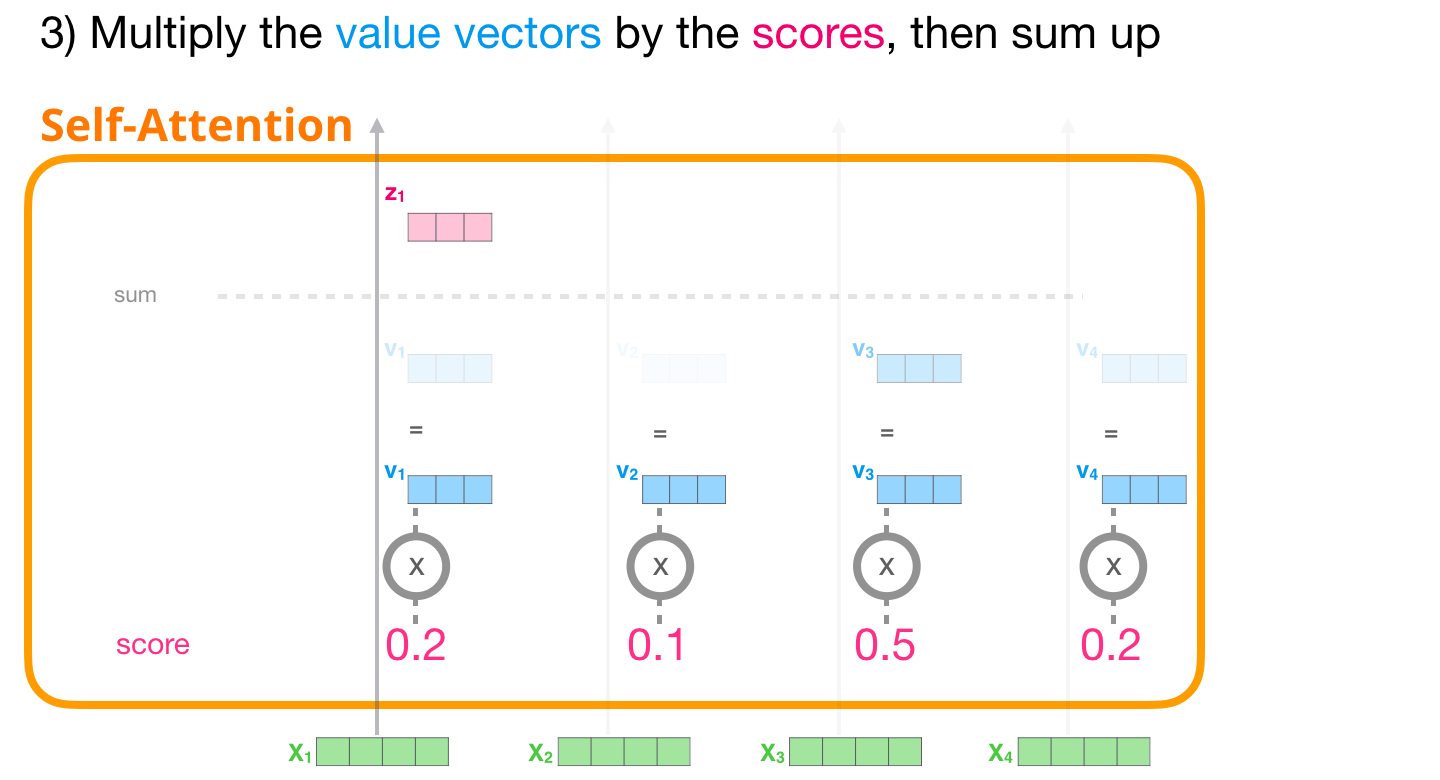
スコアが低いほど、値ベクトルがより透明になります。これは、小さな数を掛けるとベクトルの値がどのように希釈されるかを示しています。
各パスに対して同じ操作を行うと、トークンの適切なコンテキストを含む各トークンを表すベクトルになります。これらは、Transformer ブロック (フィードフォワード ニューラル ネットワーク) の次のサブレイヤーに提示されます。
イラスト化された仮面の自己注意
トランスフォーマーの自己注意のステップの内部を見たので、マスクされた自己注意の説明に進みましょう。マスクされた自己注意は、ステップ 2 以外は自己注意と同じです。モデルには入力として 2 つのトークンしかなく、2 番目のトークンを観察していると仮定します。この場合、最後の 2 つのトークンがマスクされます。そのため、モデルはスコアリング ステップに干渉します。基本的に、将来のトークンを常に 0 としてスコア付けするため、モデルは将来の単語にピークを迎えることができません。
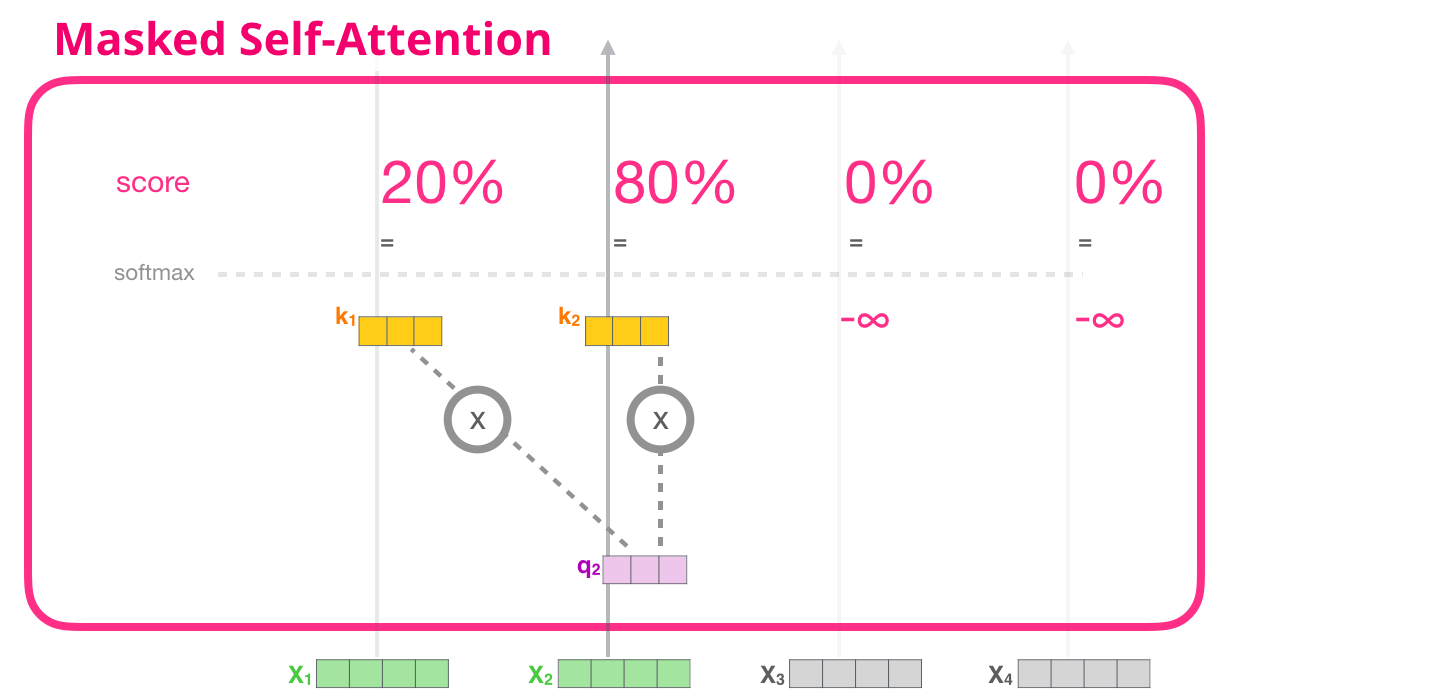
このマスキングは、アテンション マスクと呼ばれるマトリックスとして実装されることがよくあります。一連の 4 つの単語を考えてみましょう (「ロボットは命令に従わなければならない」など)。言語モデリングのシナリオでは、このシーケンスは 4 つのステップ (単語ごとに 1 つ) に吸収されます (ここでは、すべての単語がトークンであると仮定します)。これらのモデルはバッチで動作するため、このおもちゃのモデルのバッチ サイズは 4 であると想定できます。これは、シーケンス全体 (4 つのステップを含む) を 1 つのバッチとして処理します。
マトリックス形式では、クエリ マトリックスにキー マトリックスを掛けてスコアを計算します。次のように視覚化してみましょう。ただし、単語の代わりに、そのセル内のその単語に関連付けられたクエリ (またはキー) ベクトルが存在します。
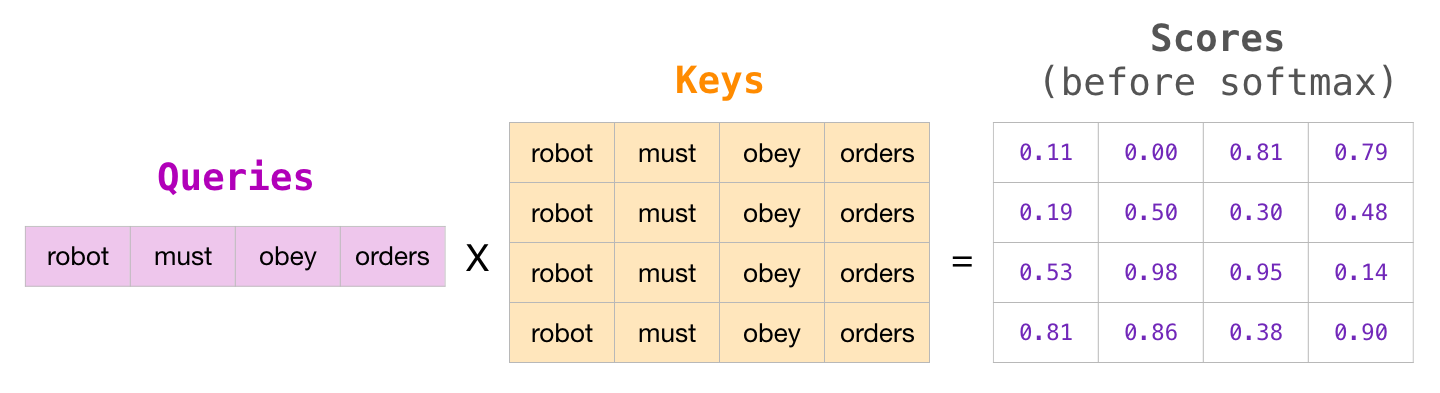
乗算の後、アテンション マスクの三角形を叩きます。マスクするセルを -infinity または非常に大きな負の数 (GPT2 では -10 億など) に設定します。
次に、各行にソフトマックスを適用すると、自己注意に使用する実際のスコアが生成されます。
このスコア表の意味は次のとおりです。
- モデルがデータセット内の最初の例 (行 #1) を処理すると、1 つの単語 (「ロボット」) のみが含まれ、その単語に 100% の注意が向けられます。
- モデルがデータセット内の 2 番目の例 (行 #2) を処理するとき (「ロボットが必要」) という単語を含む場合、「しなければならない」という単語を処理するとき、その注意の 48% は「ロボット」に向けられ、52% は「ロボット」に向けられます。その注意の % は「しなければならない」に集中します。
- 等々
GPT-2 仮面自己注意
GPT-2 のマスクされた注意について詳しく見ていきましょう。
評価時間: 一度に 1 つのトークンを処理する
マスクされた自己注意が機能するのとまったく同じように GPT-2 を動作させることができます。しかし、評価中、各反復の後にモデルが新しい単語を 1 つ追加するだけの場合、既に処理されたトークンの以前のパスに沿って自己注意を再計算するのは非効率的です。
この場合、最初のトークンを処理します (ここでは無視<s>します)。
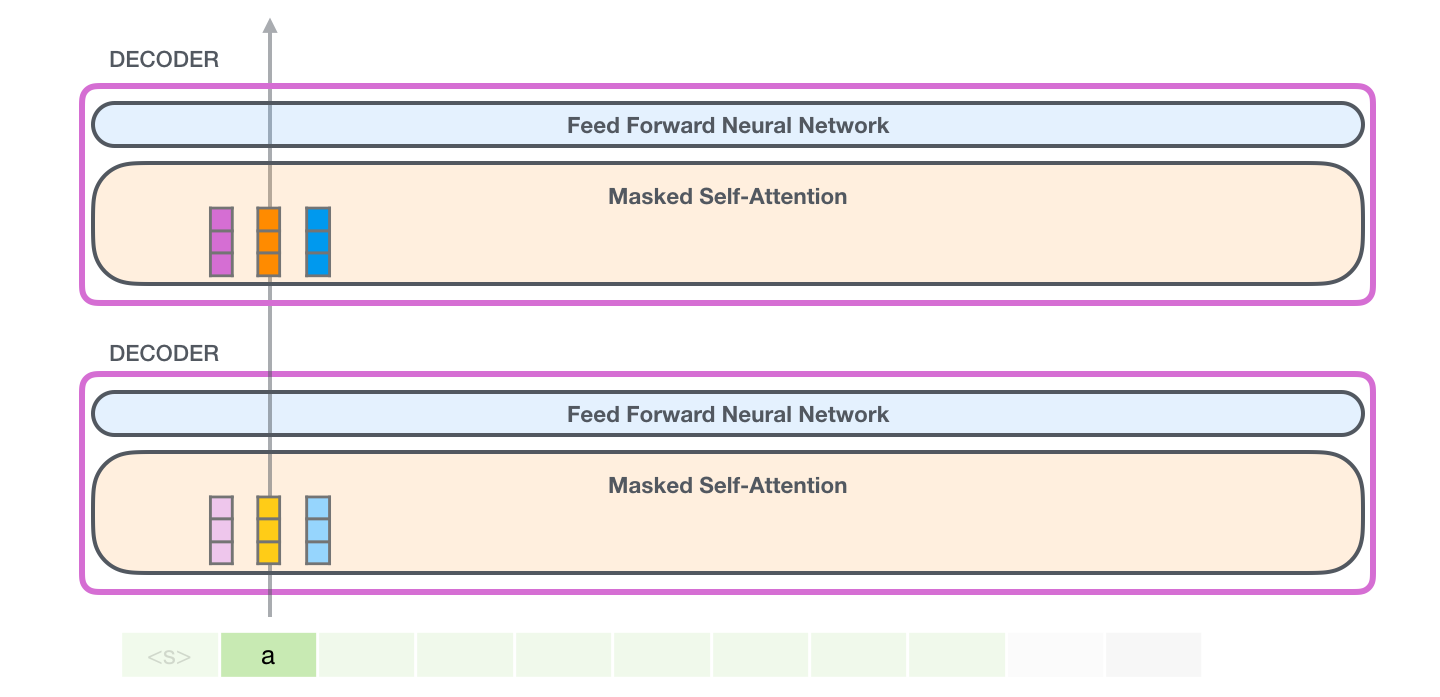
GPT-2 は、aトークンのキー ベクトルと値ベクトルを保持します。すべての自己注意層は、そのトークンのそれぞれのキーと値のベクトルを保持します。
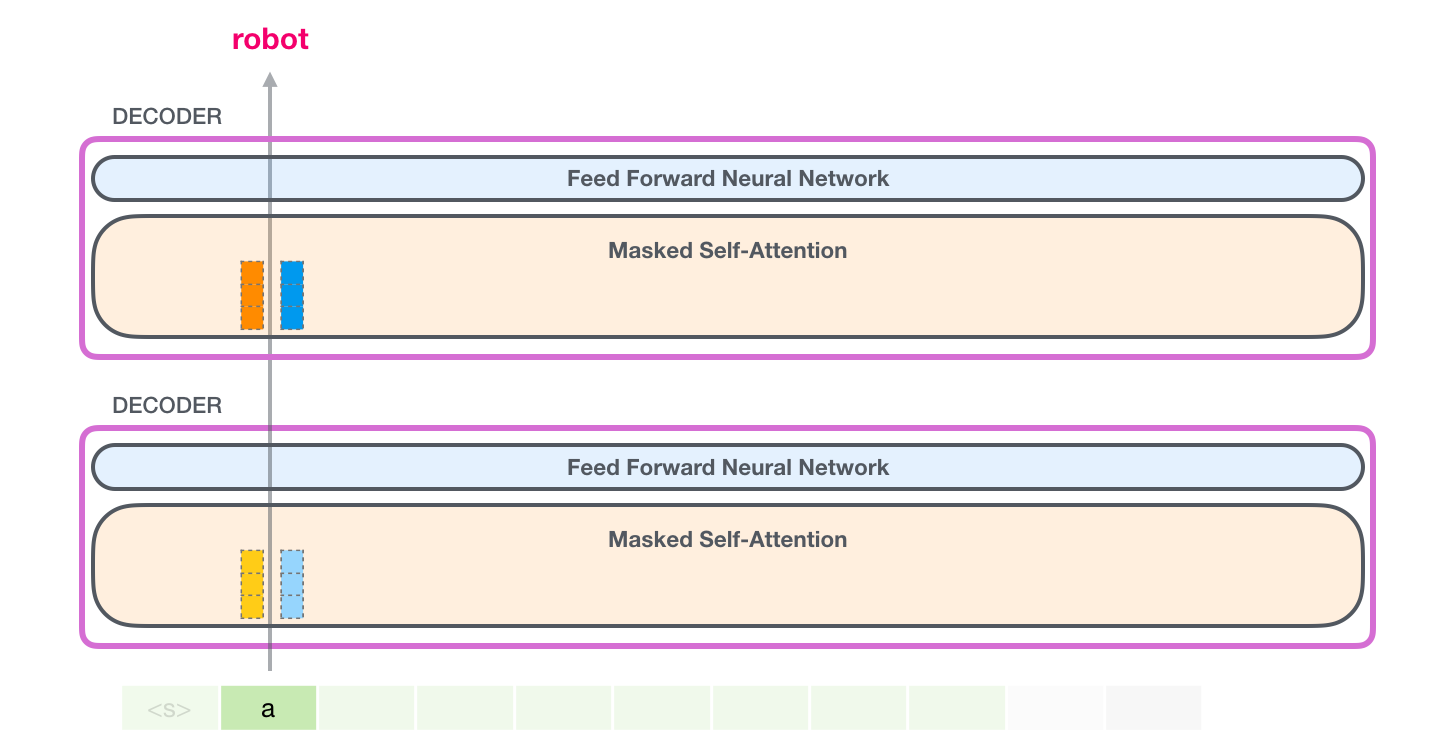
次の反復では、モデルが単語 を処理するときに、トークンrobotのクエリ、キー、および値のクエリを生成する必要はありません。a最初の反復で保存したものを再利用するだけです。
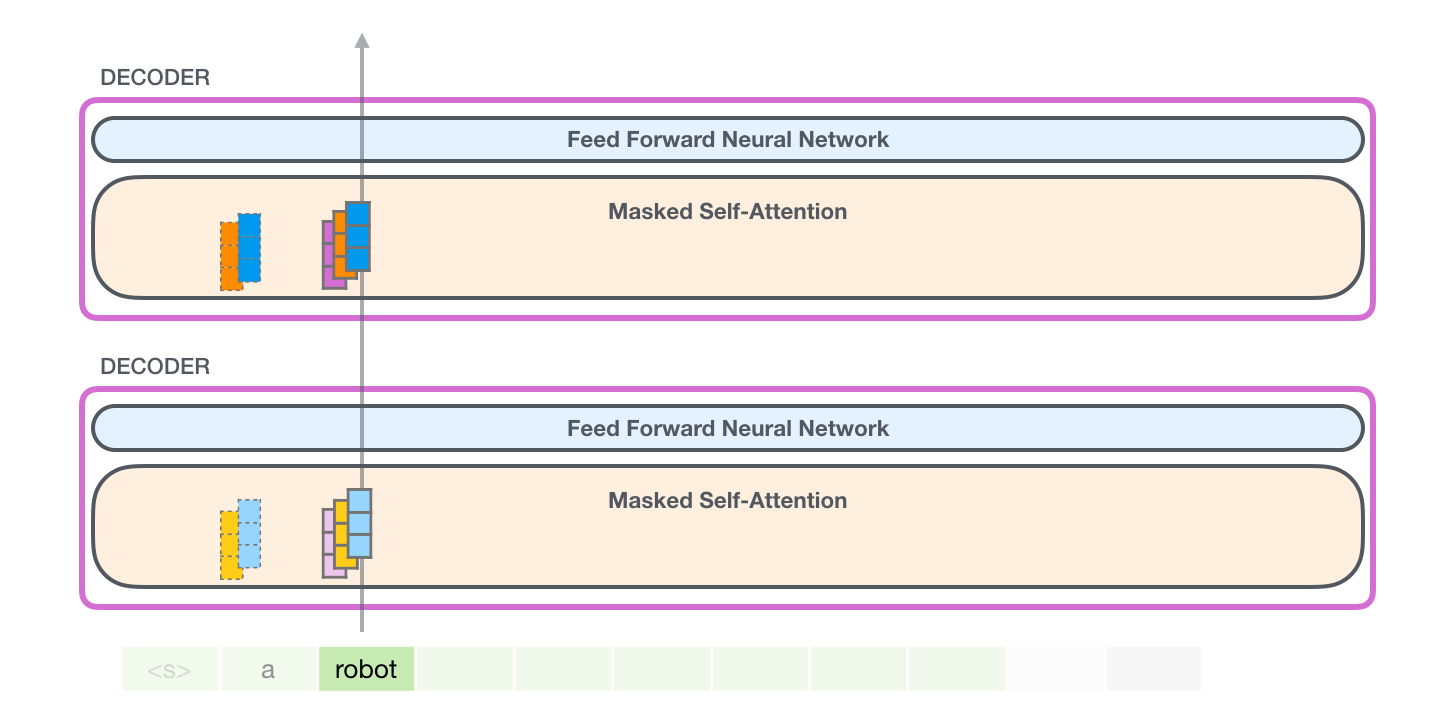
GPT-2 自己注意: 1- クエリ、キー、および値の作成
モデルが単語 を処理していると仮定しましょうit。一番下のブロックについて話している場合、そのトークンの入力は、itスロット #9 の埋め込み + 位置エンコーディングになります。
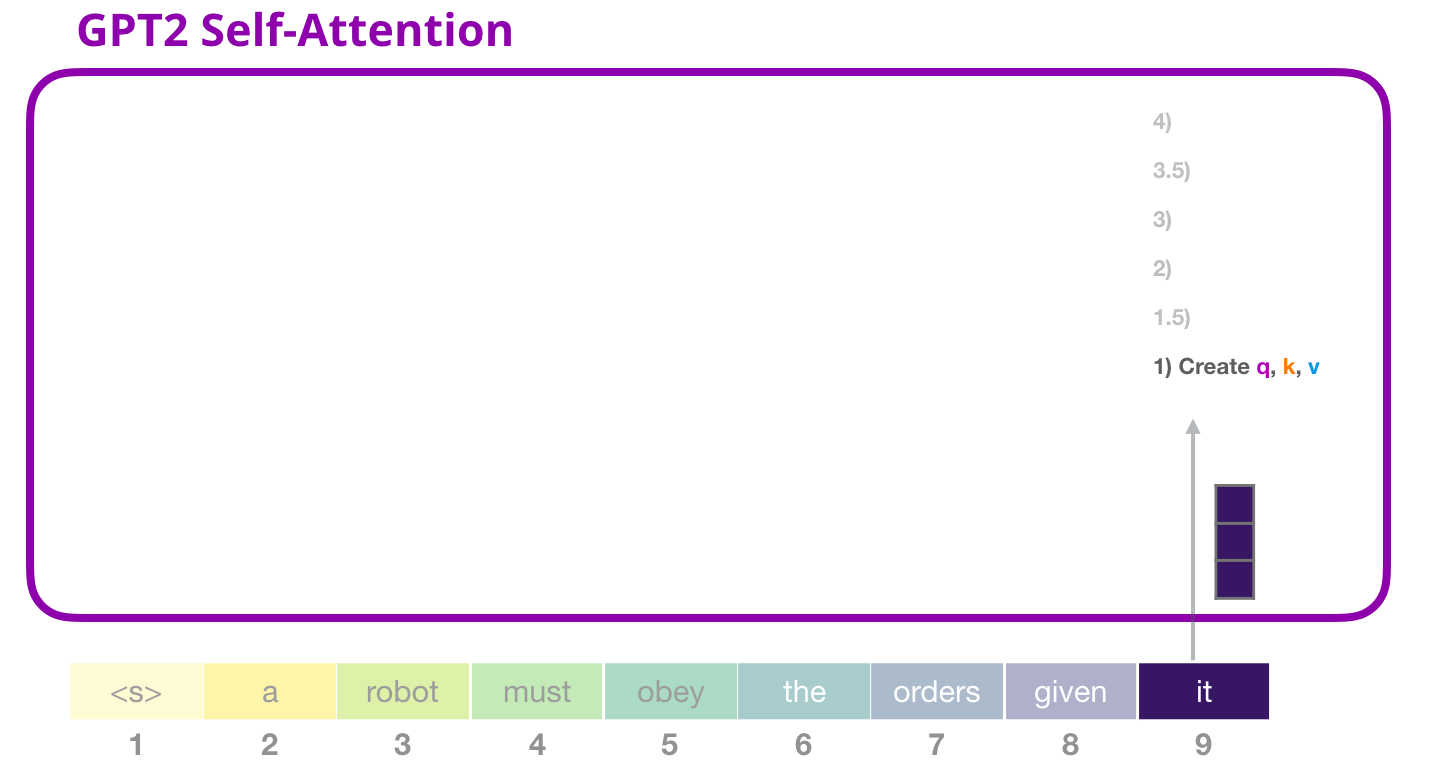
Transformer のすべてのブロックには独自の重みがあります (記事の後半で詳しく説明します)。最初に遭遇するのは、クエリ、キー、および値を作成するために使用する重み行列です。
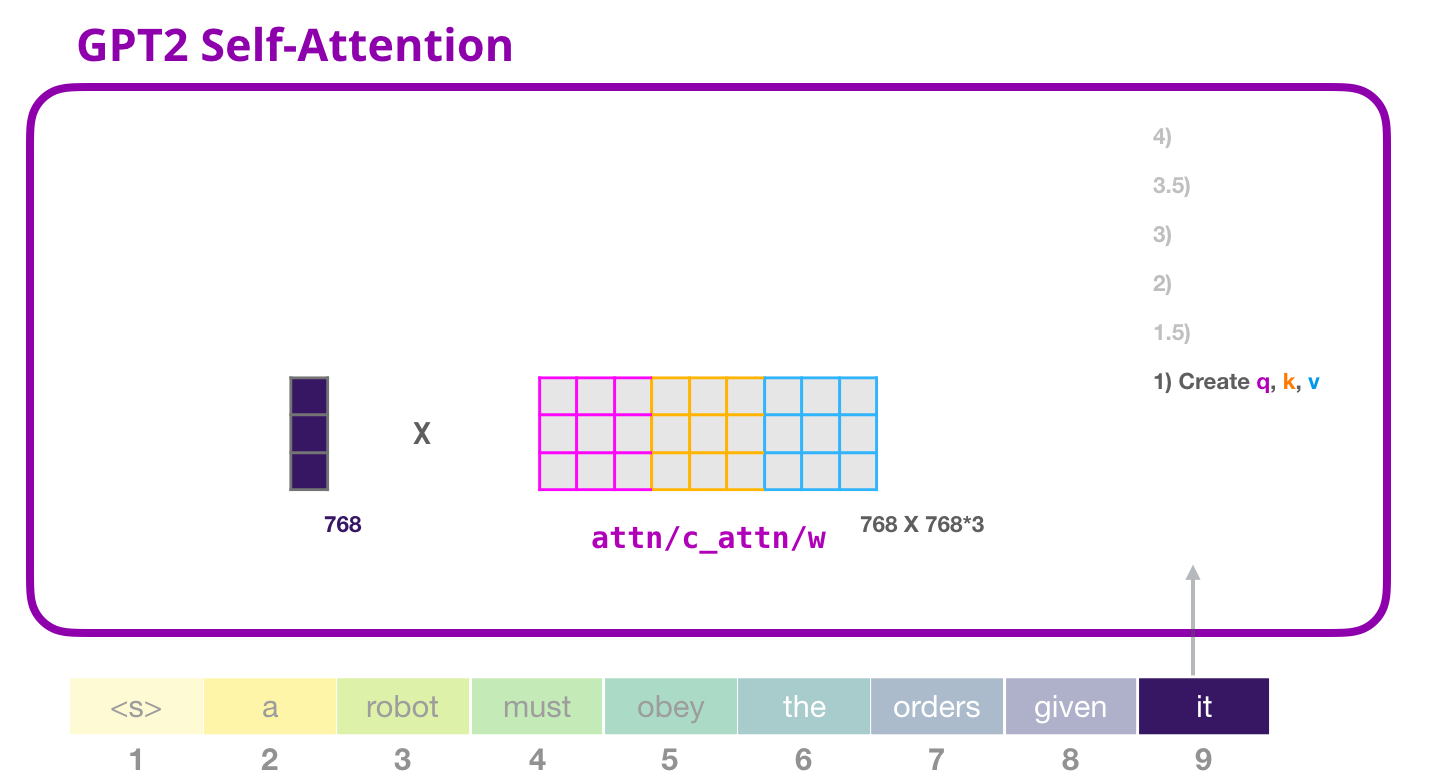
Self-Attention は、その入力に重み行列を掛けます (ここでは示されていませんが、バイアス ベクトルを追加します)。
乗算の結果、基本的に単語のクエリ、キー、および値のベクトルを連結したベクトルが得られますit。
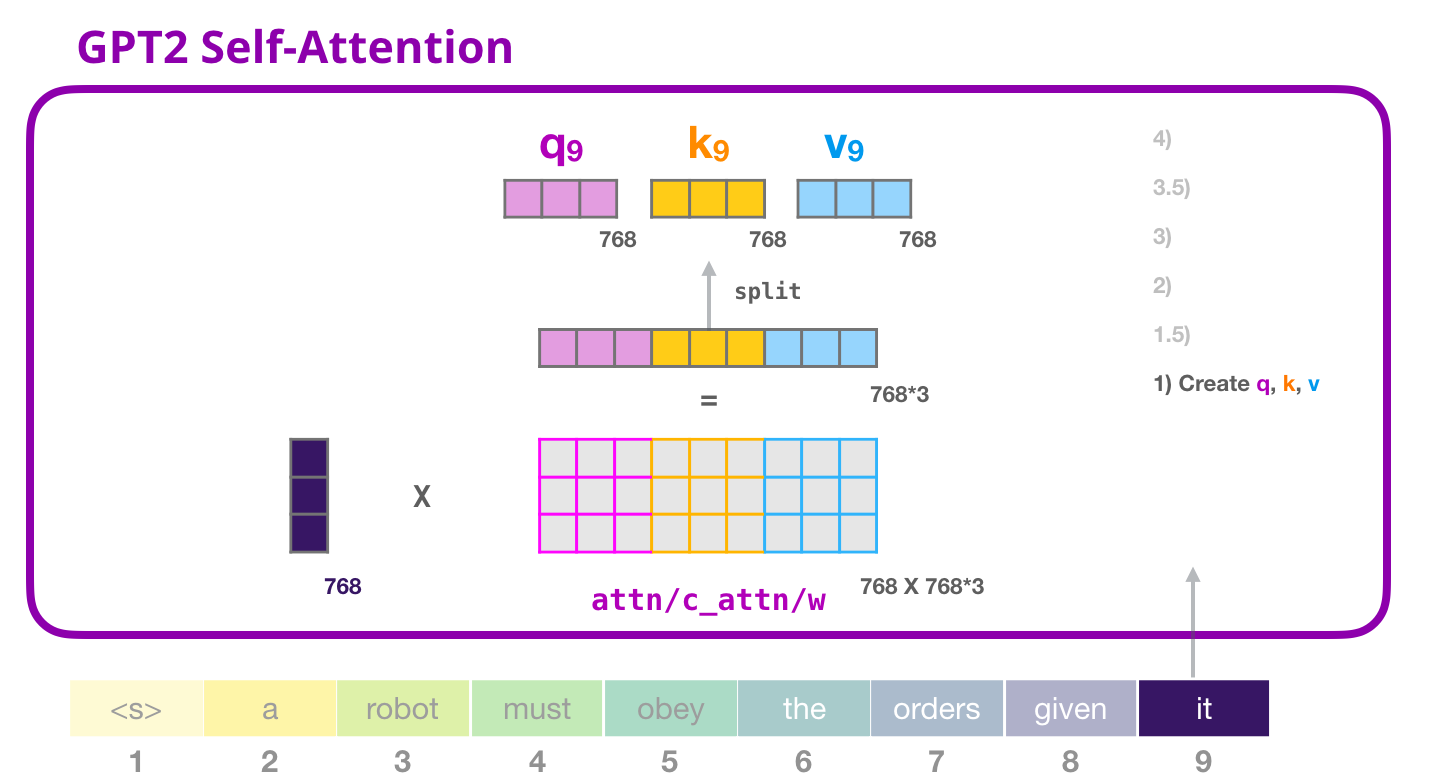
入力ベクトルにアテンション ウェイト ベクトルを掛けると (その後にバイアス ベクトルを追加すると)、このトークンのキー、値、およびクエリ ベクトルが得られます。
GPT-2 Self-attention: 1.5- 注意の頭への分割
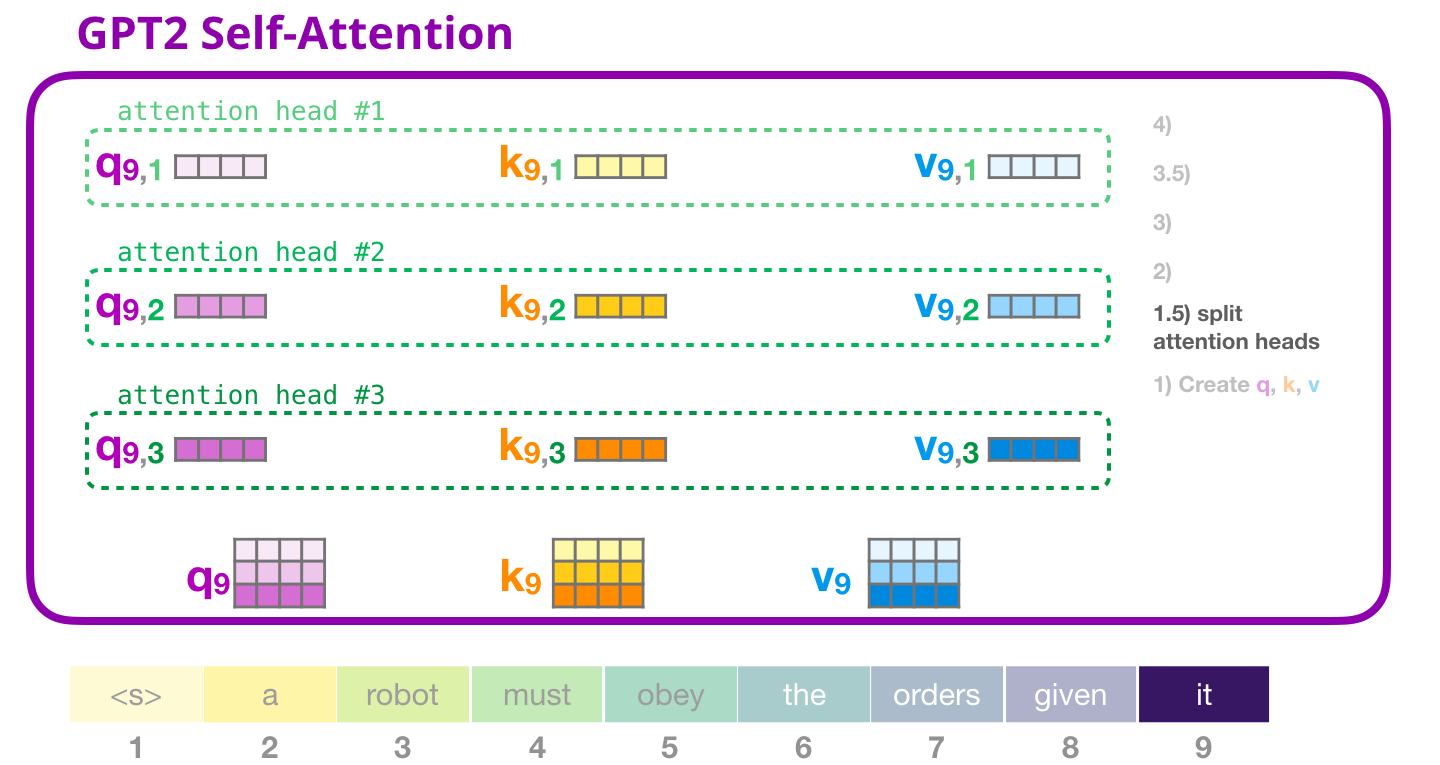
前の例では、「マルチヘッド」部分を無視して、自己注意に直接飛び込みました。今、その概念に光を当てることは有益でしょう。自己注意は、Q、K、V ベクトルのさまざまな部分で複数回実行されます。アテンション ヘッドを「分割」することは、単純に長いベクトルを行列に再形成することです。小さな GPT2 には 12 個のアテンション ヘッドがあるため、それが再形成されたマトリックスの最初の次元になります。
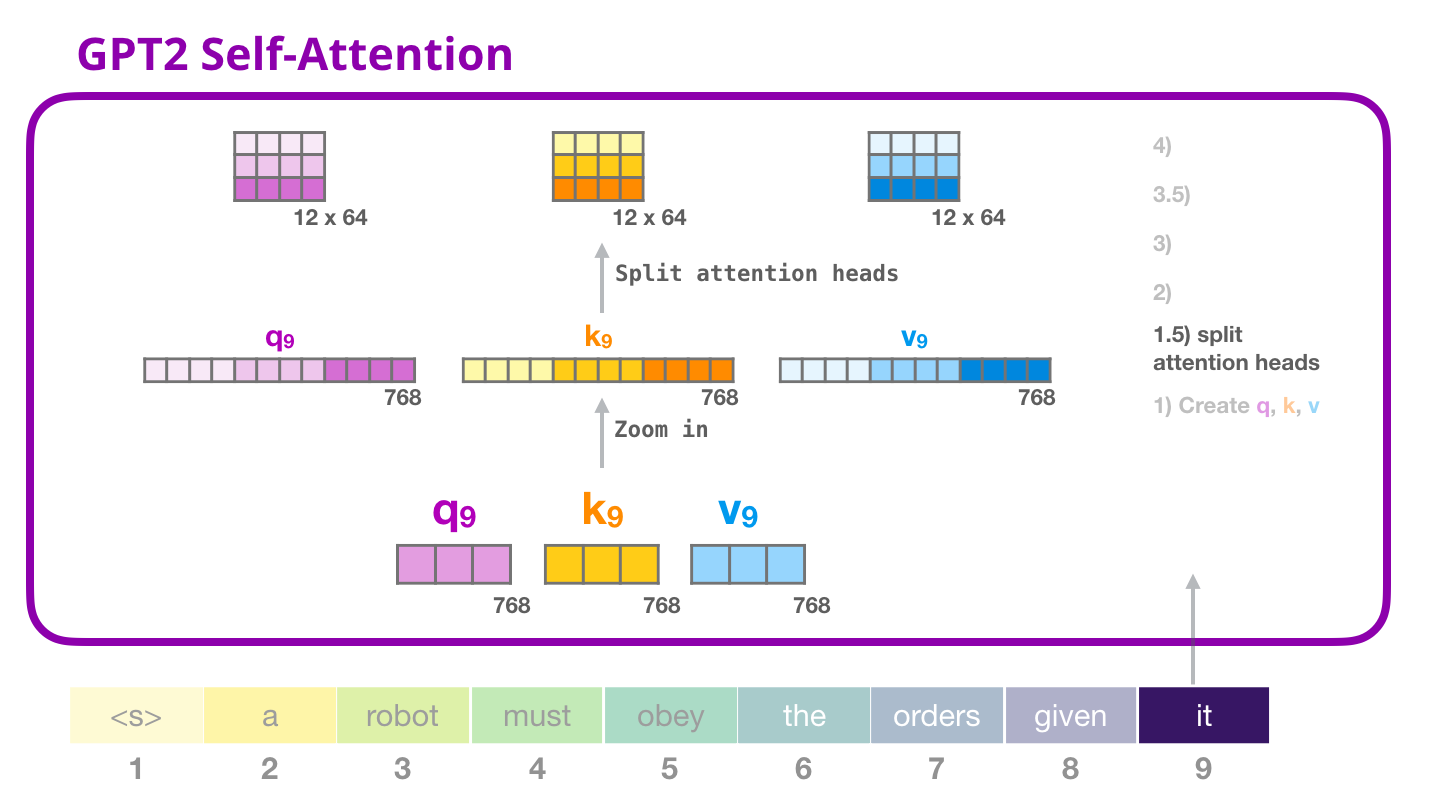
前の例では、1 つのアテンション ヘッドの内部で何が起こっているかを見てきました。複数のアテンション ヘッドを考える 1 つの方法は次のとおりです (12 個のアテンション ヘッドのうち 3 つだけを視覚化する場合)。
GPT-2 自己注意: 2- 採点
これでスコアリングに進むことができます – 1 つのアテンション ヘッドだけを見ている (そして、他のすべてのアテンション ヘッドが同様の操作を行っている) ことを知っています。
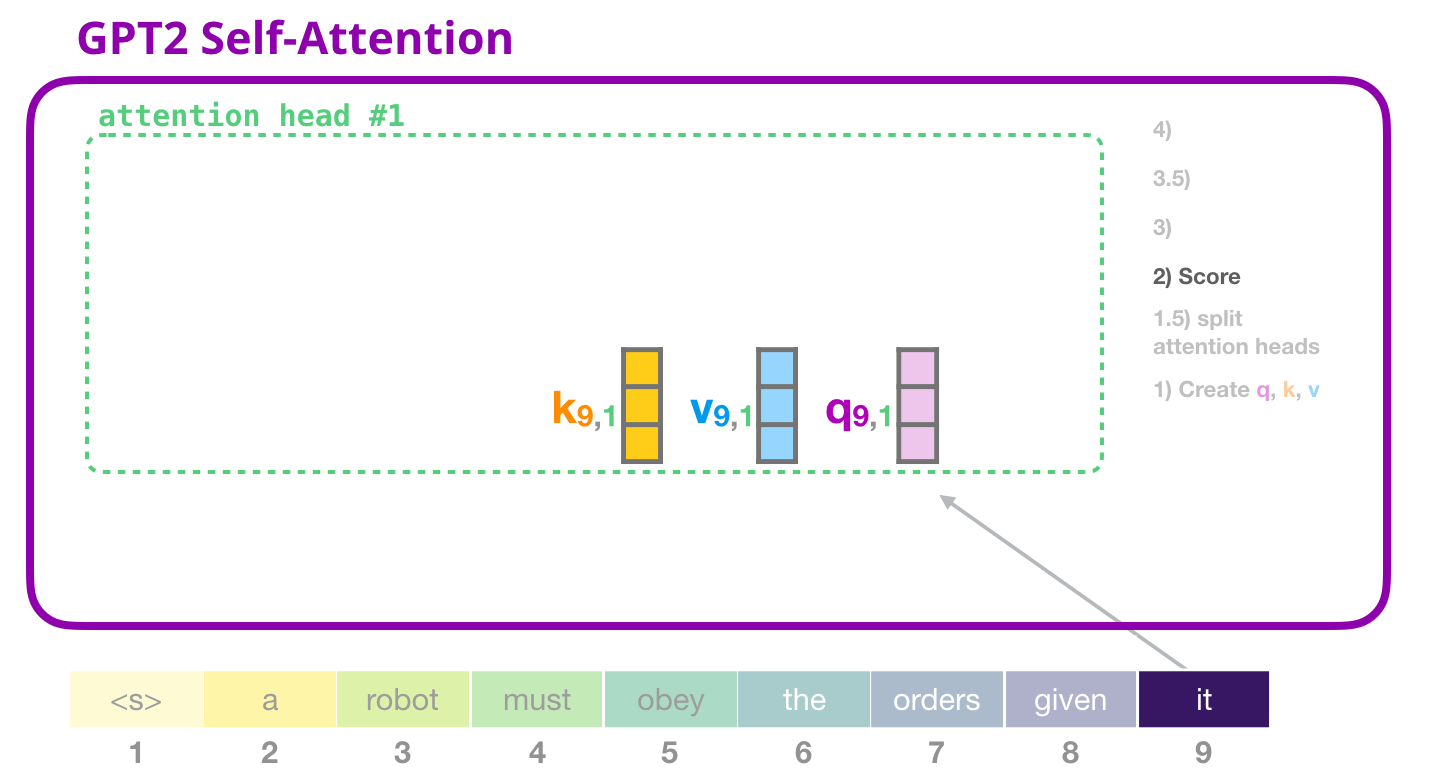
これで、トークンは他のトークンのすべてのキー (前の反復でアテンション ヘッド #1 で計算されたもの) に対してスコアを取得できます。
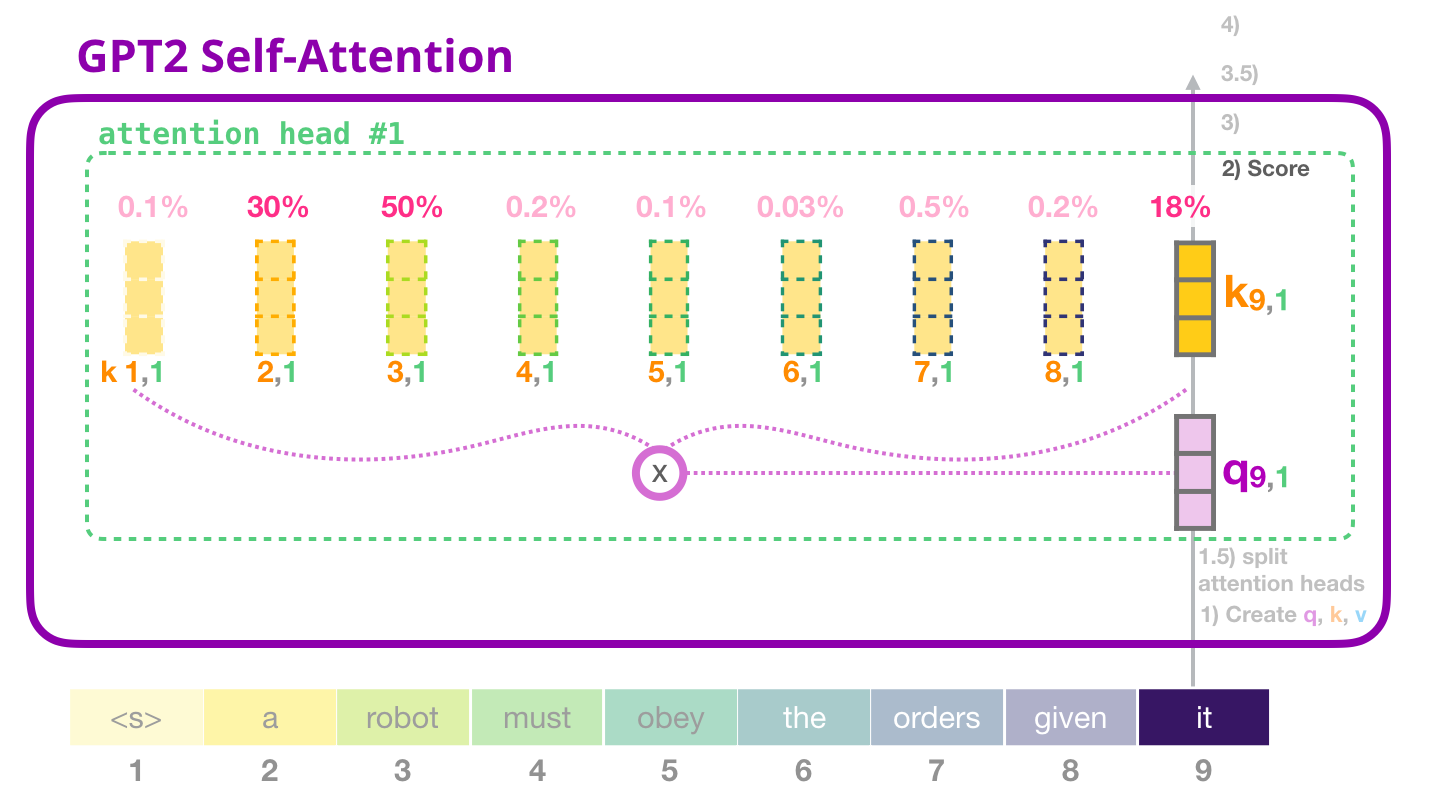
GPT-2 自己注意: 3- 合計
前に見たように、各値をそのスコアで乗算し、それらを合計して、アテンション ヘッド #1 の自己注意の結果を生成します。
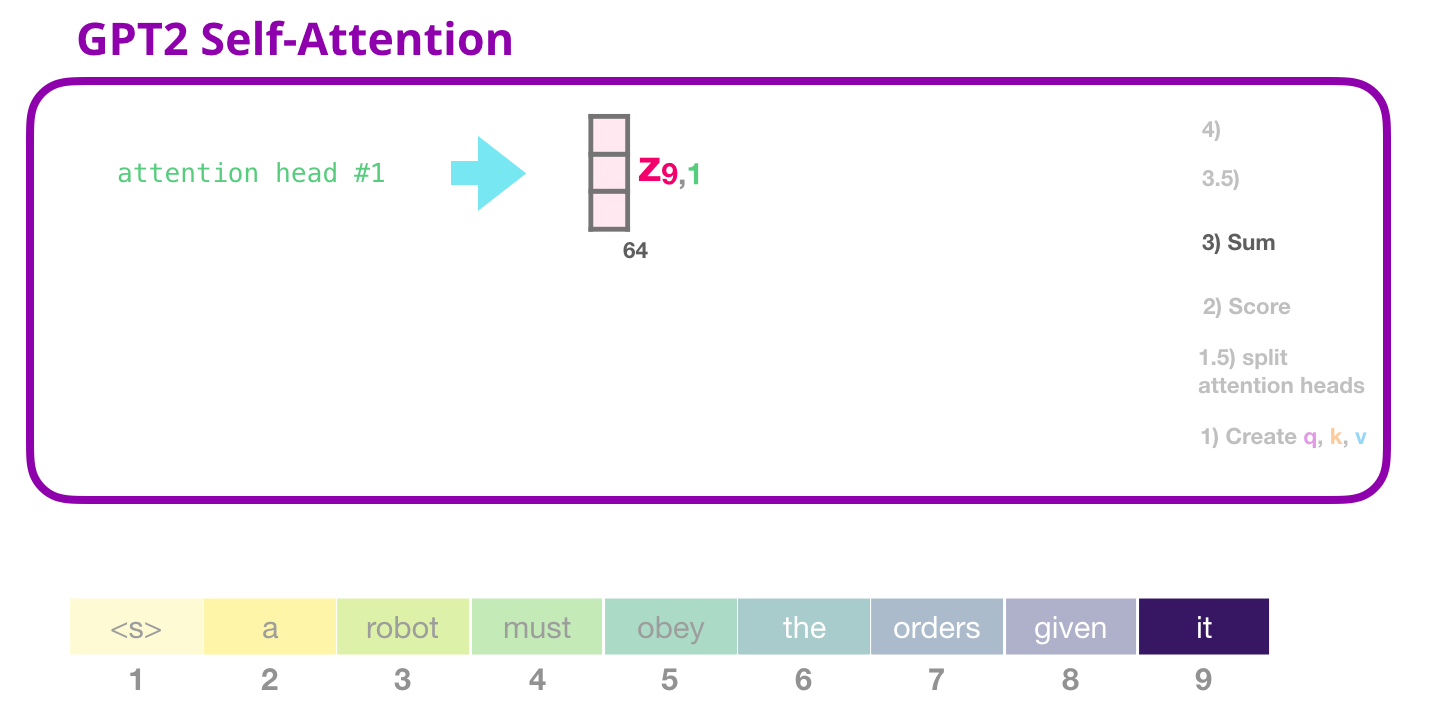
GPT-2 Self-attention: 3.5- アテンション ヘッドをマージする
さまざまなアテンション ヘッドを処理する方法は、最初にそれらを 1 つのベクトルに連結することです。
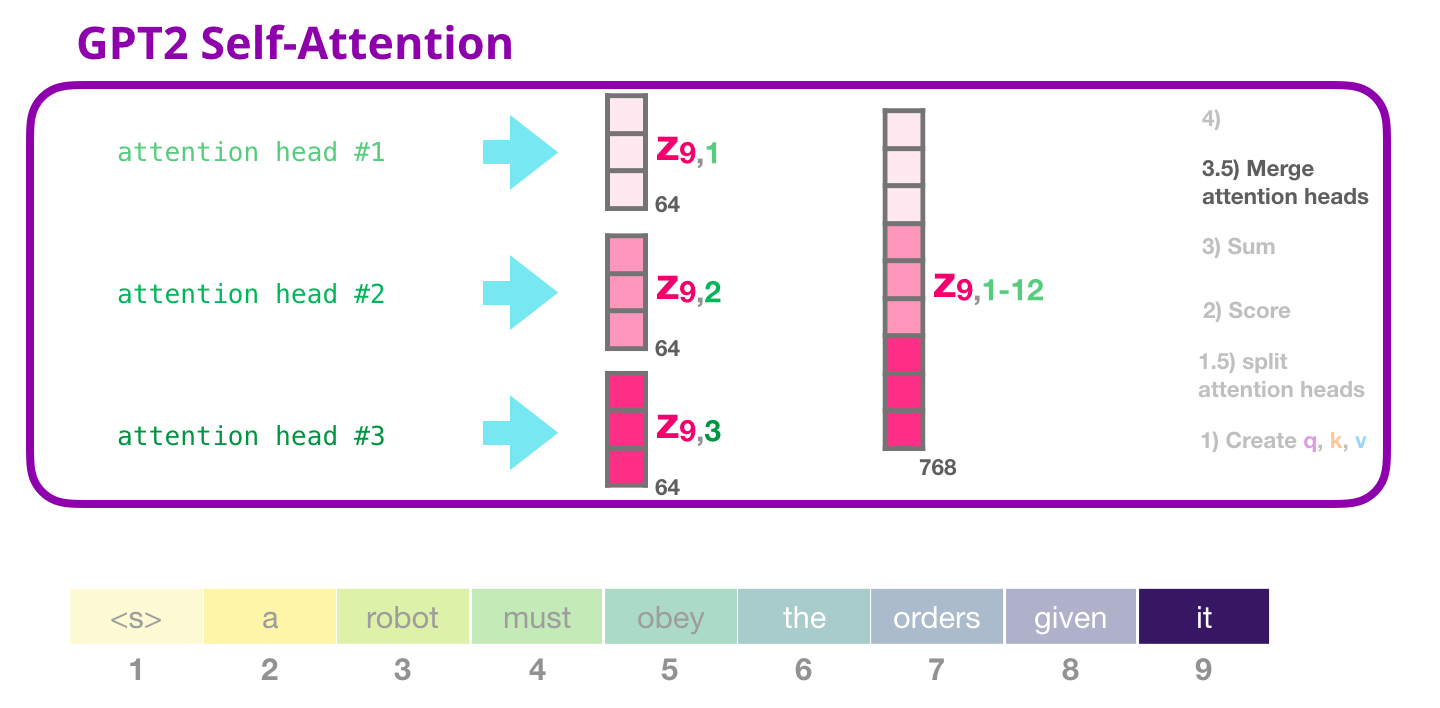
しかし、ベクターはまだ次のサブレイヤーに送信する準備ができていません。最初に、このフランケンシュタインのような隠れた状態の怪物を均質な表現に変える必要があります。
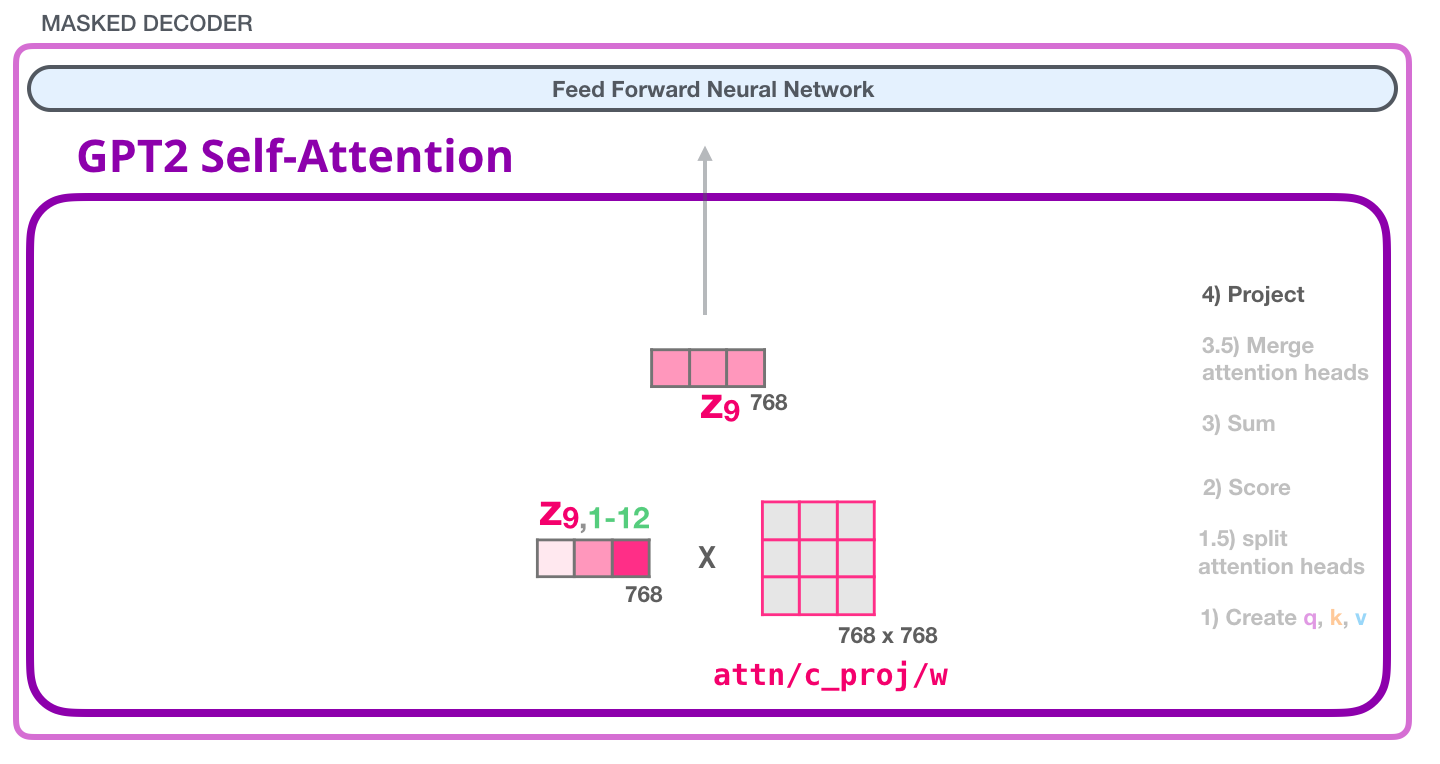
GPT-2 自己注意: 4- 投影
連結された自己注意の結果を、フィードフォワード ニューラル ネットワークが処理できるベクトルに最適にマッピングする方法をモデルに学習させます。ここに、アテンション ヘッドの結果をセルフ アテンション サブレイヤーの出力ベクトルに投影する 2 番目の大きな重み行列があります。
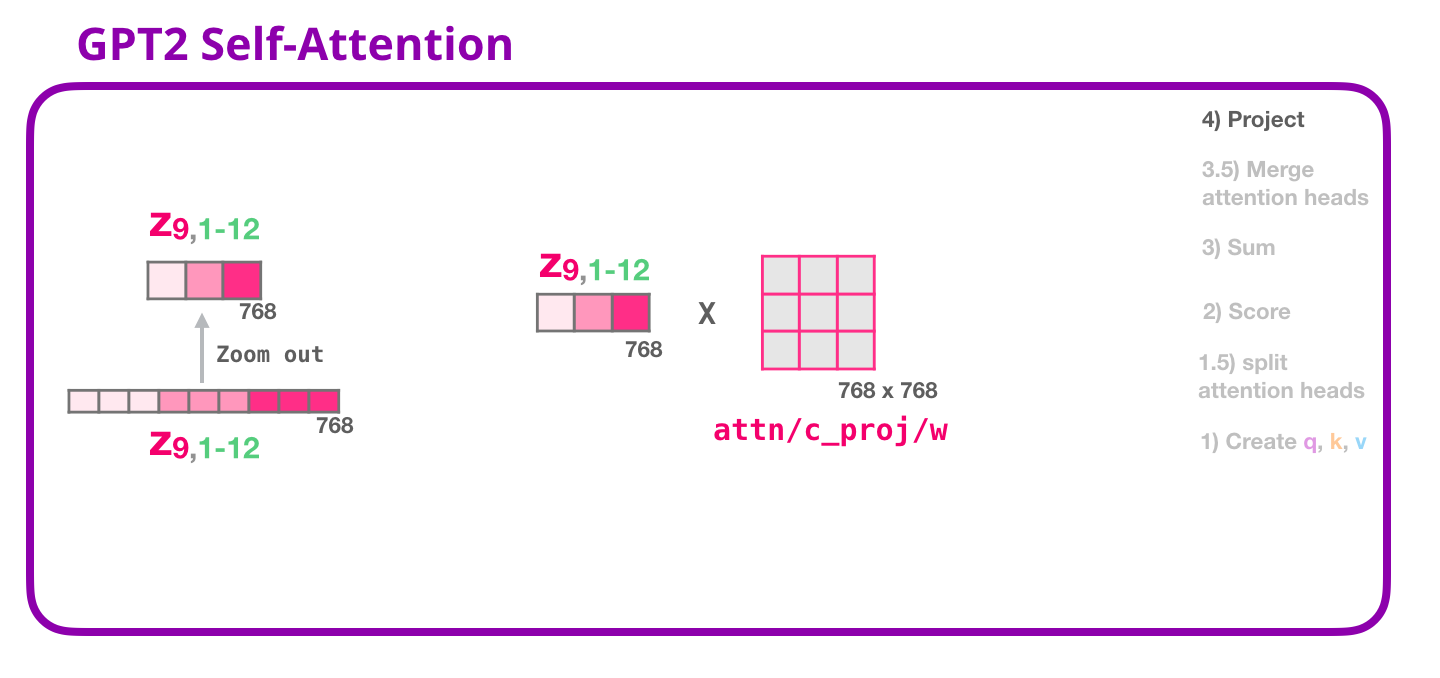
これで、次のレイヤーに送信できるベクトルが作成されました。
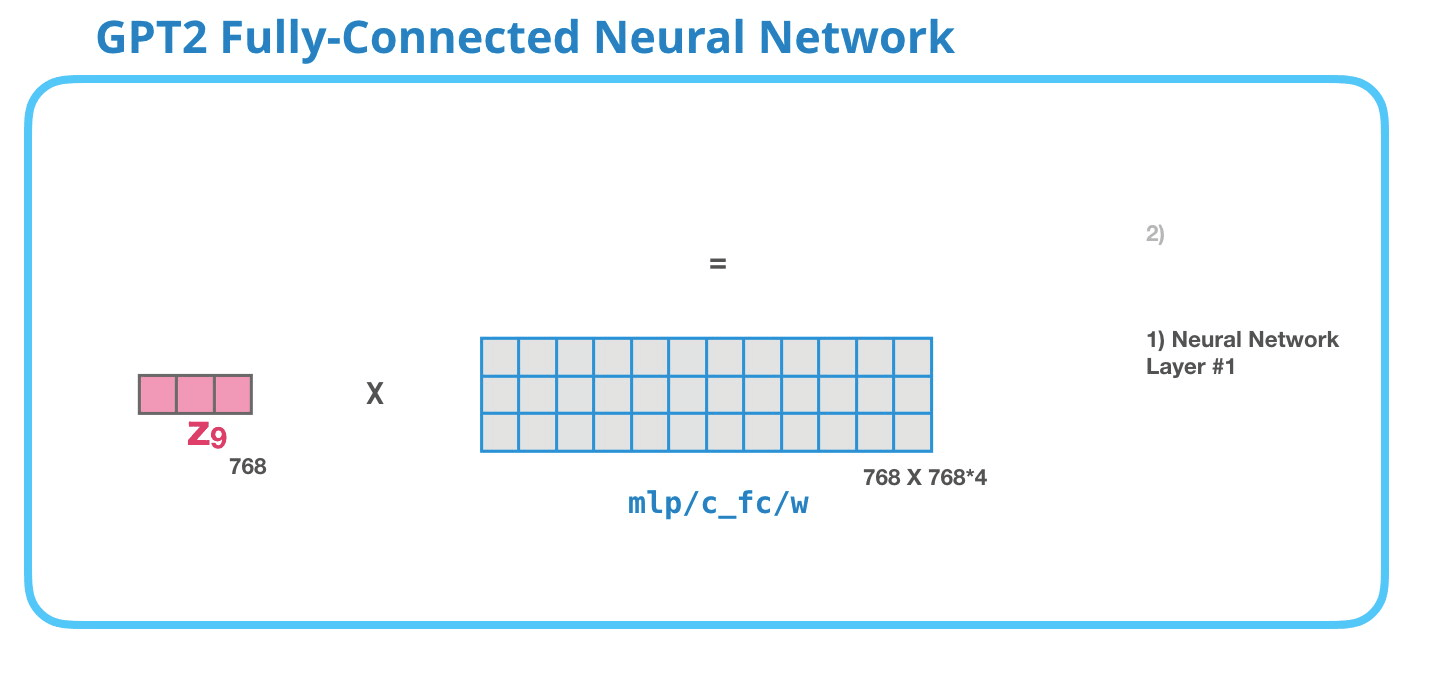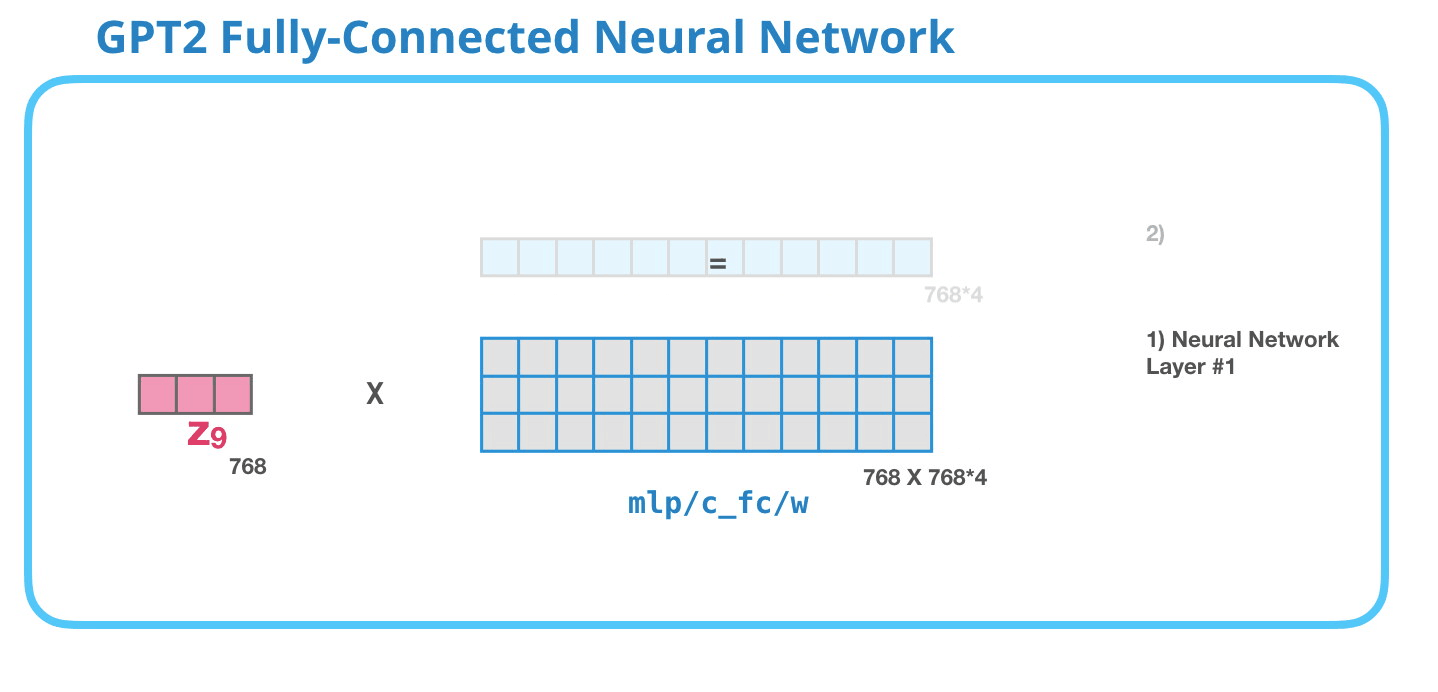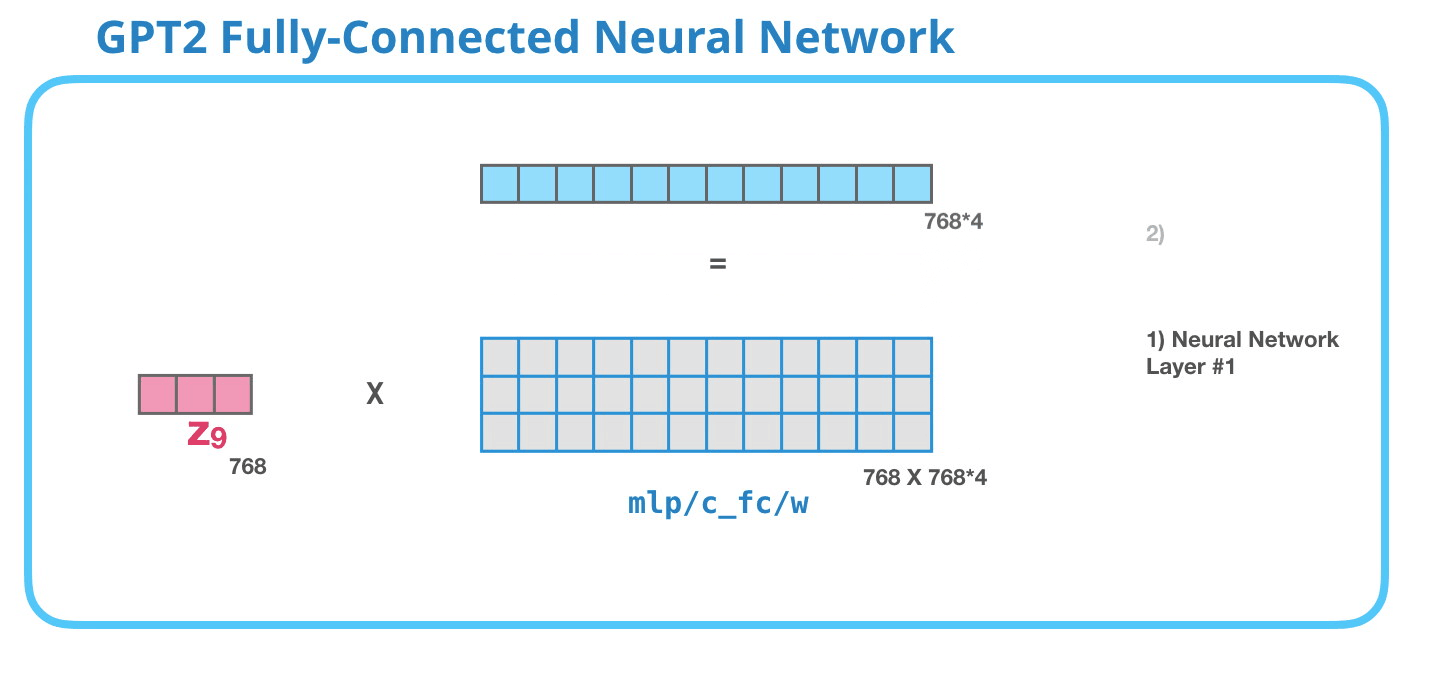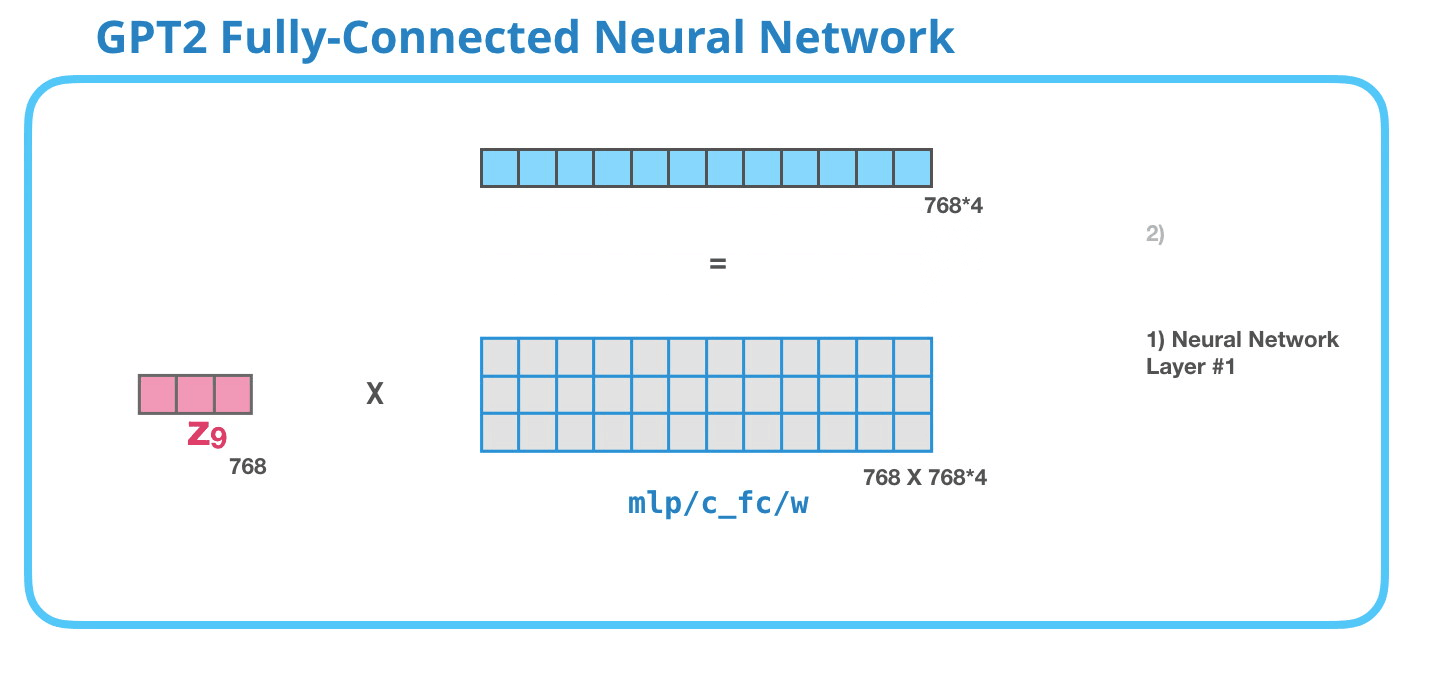
GPT-2 完全に接続されたニューラル ネットワーク: レイヤー #1
完全に接続されたニューラル ネットワークは、自己注意がその表現に適切なコンテキストを含めた後、ブロックがその入力トークンを処理する場所です。2つのレイヤーで構成されています。最初のレイヤーはモデルのサイズの 4 倍です (GPT2 small は 768 なので、このネットワークは 768*4 = 3072 ユニットになります)。なんで4回?これは、元の変圧器が巻かれたサイズです (モデルの寸法は 512 で、そのモデルのレイヤー #1 は 2048 でした)。これにより、これまでに投入されたタスクを処理するのに十分な表現能力がトランスフォーマー モデルに与えられるようです。
(図示せず:バイアスベクトル)
GPT-2 完全に接続されたニューラル ネットワーク: レイヤー #2 – モデル次元への射影
2 番目のレイヤーは、最初のレイヤーの結果をモデルの次元 (小さな GPT2 の場合は 768) に投影します。この乗算の結果は、このトークンの変換ブロックの結果です。
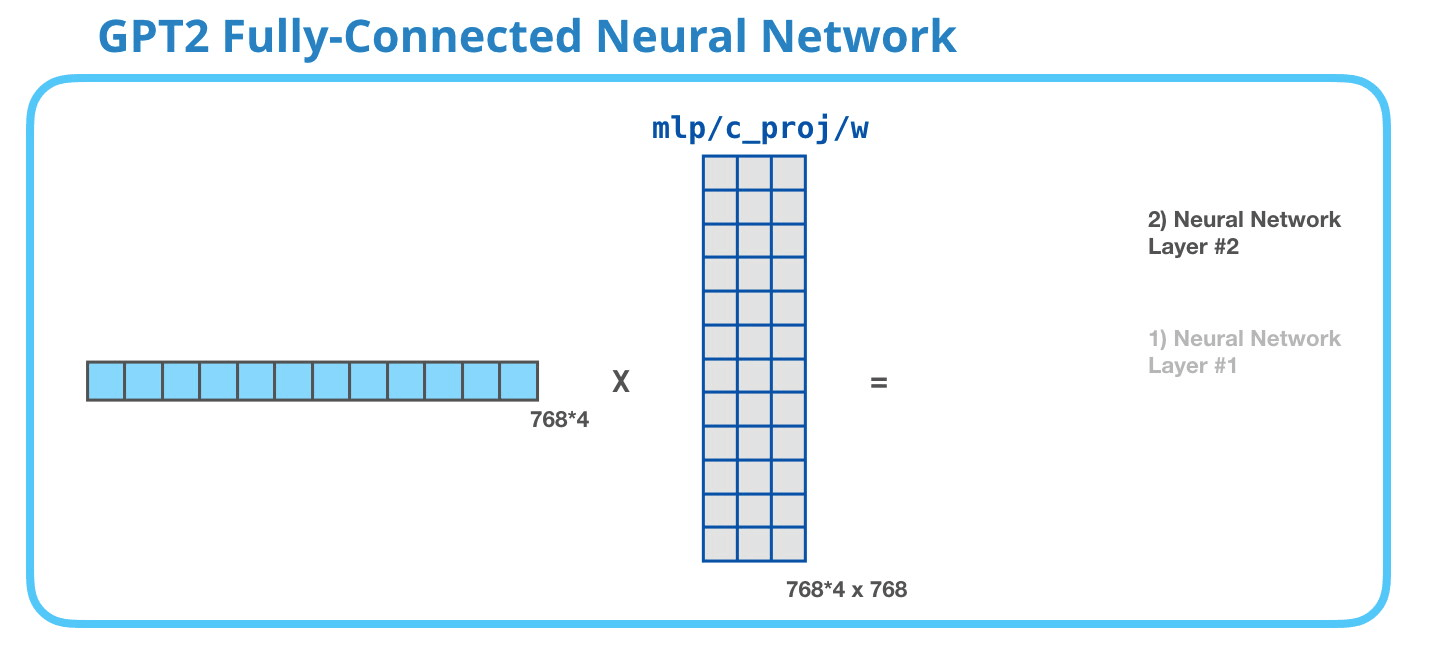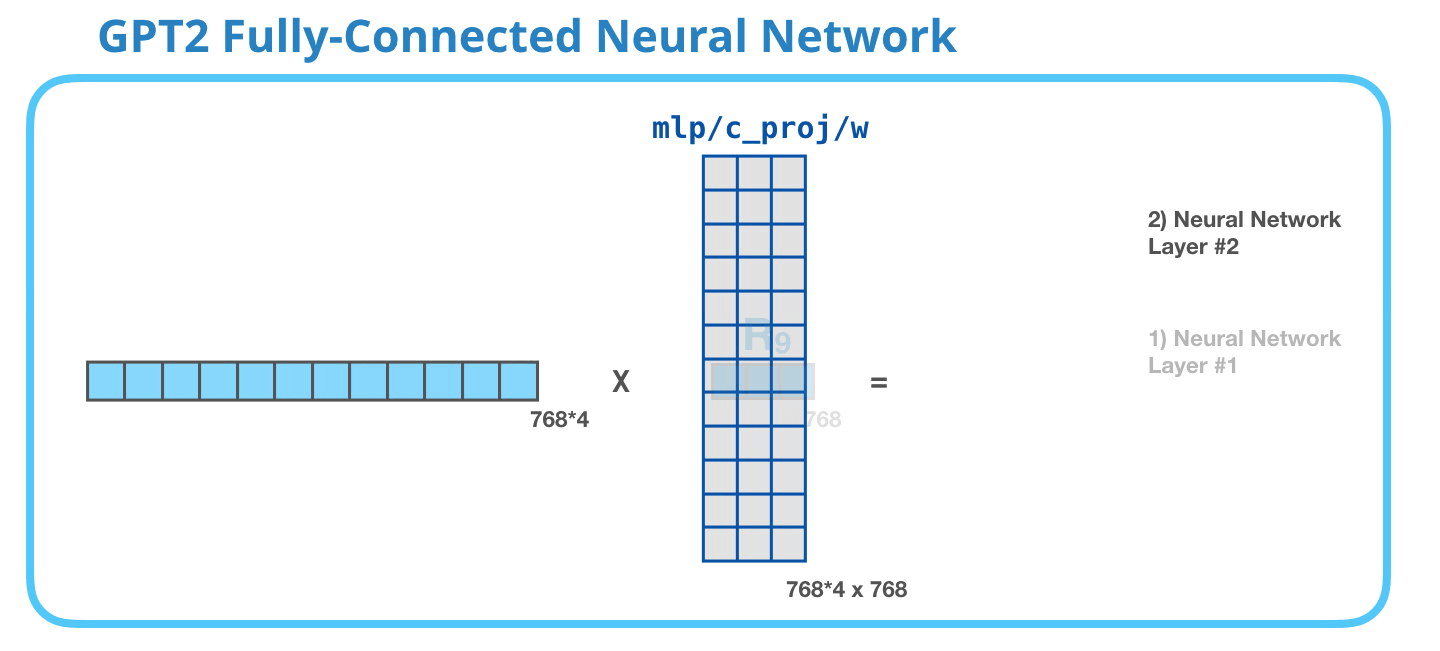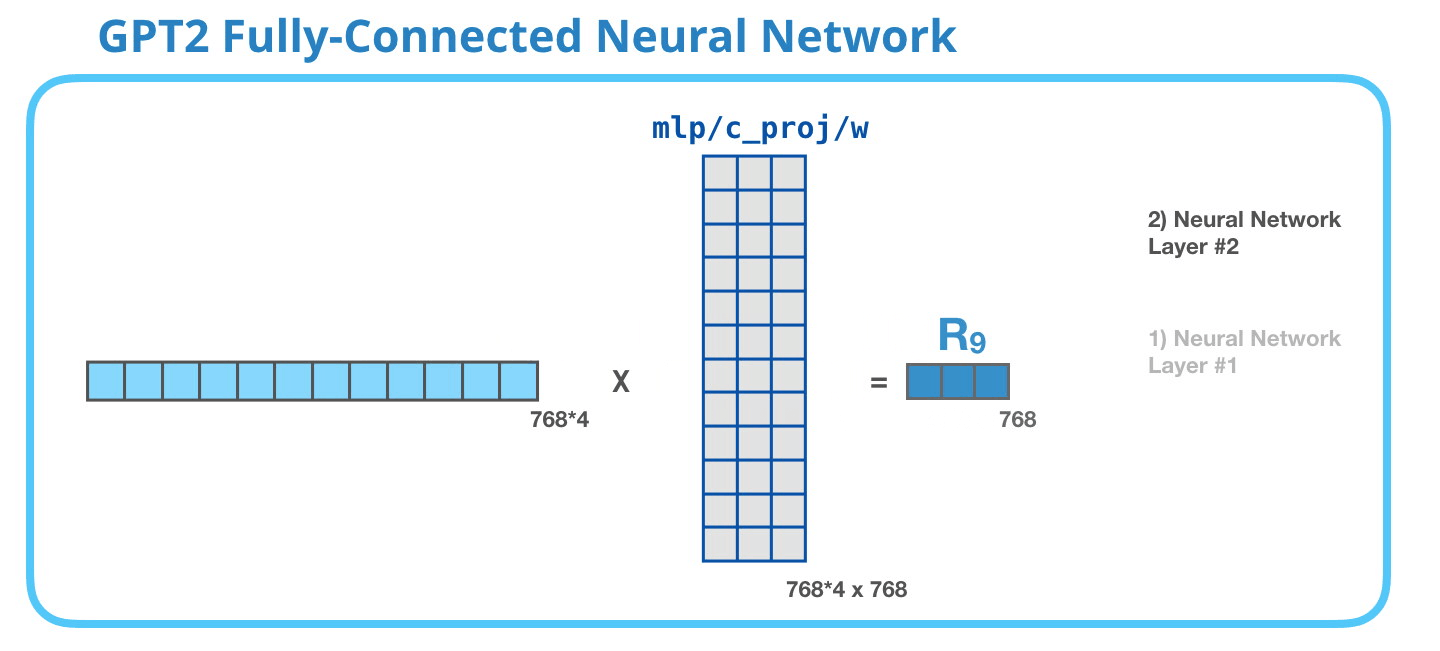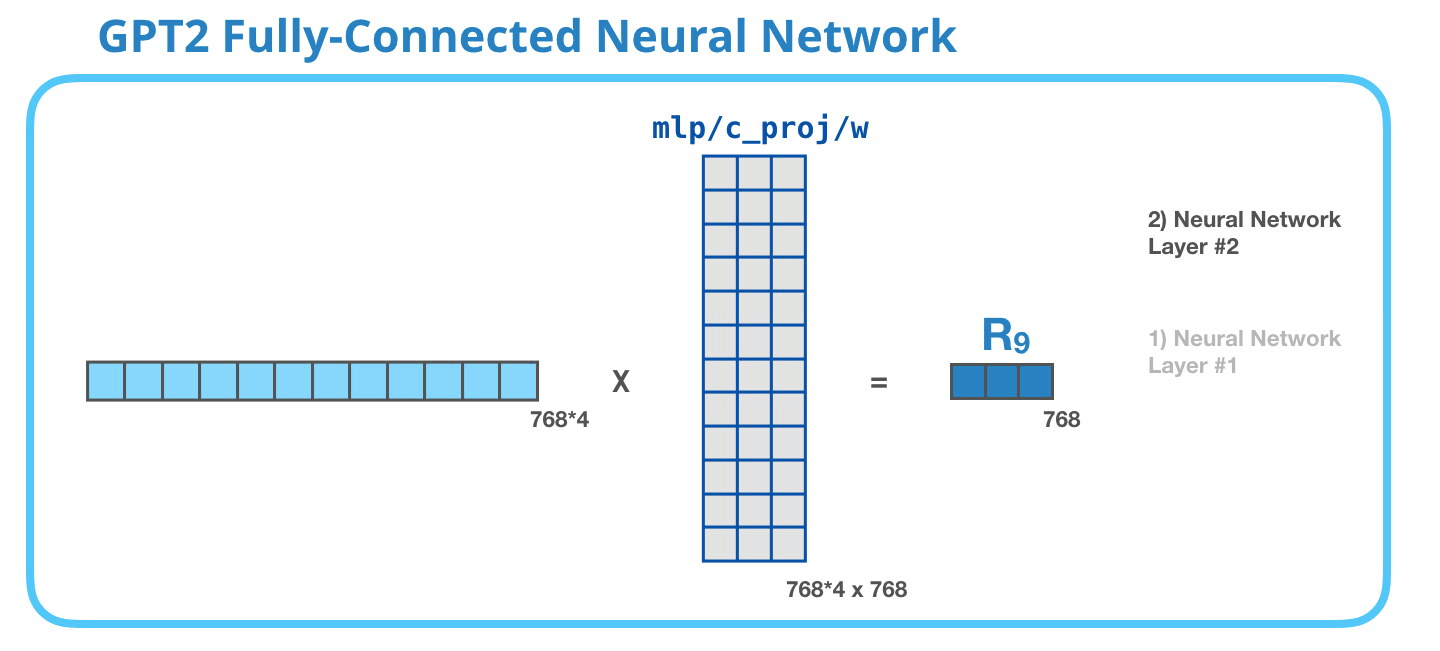
(図示せず:バイアスベクトル)
あなたはそれを作りました!
これが、これから取り上げる Transformer ブロックの最も詳細なバージョンです。これで、Transformer 言語モデルの内部で何が起こっているかについて、大部分の画像が得られました。要約すると、勇敢な入力ベクトルは次の重み行列に遭遇します。
そして、各ブロックには、これらの重みの独自のセットがあります。一方、モデルには 1 つのトークン埋め込み行列と 1 つの位置エンコーディング行列しかありません。
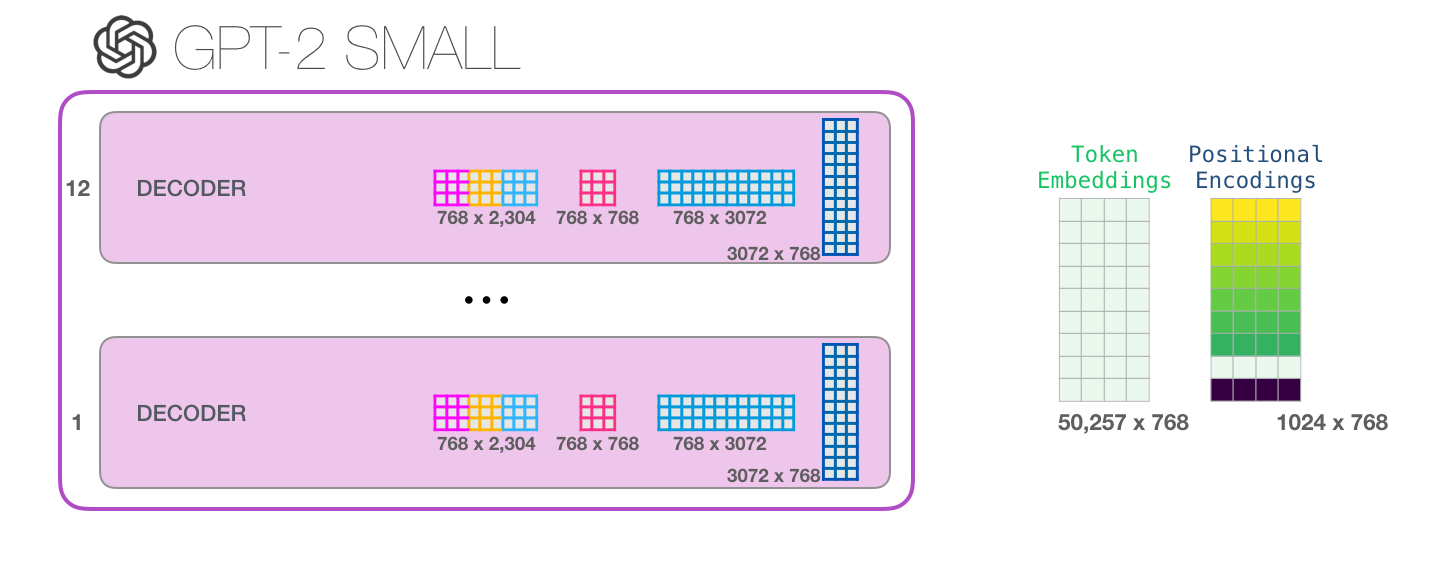
モデルのすべてのパラメーターを確認したい場合は、ここでそれらを集計しました。
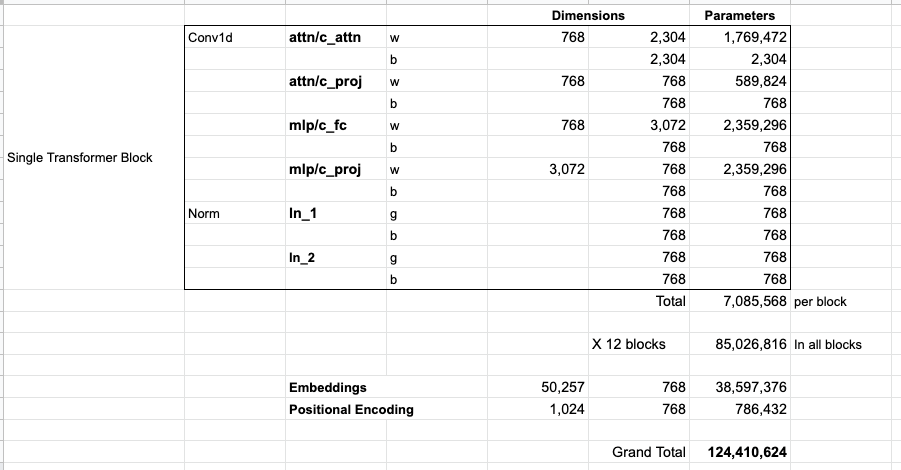
何らかの理由で、117M ではなく最大 124M のパラメーターを追加します。理由はわかりませんが、公開されたコードにはこれだけの数が含まれているようです (間違っていたら訂正してください)。
パート 3: 言語モデリングを超えて#
デコーダーのみのトランスフォーマーは、言語モデリングを超えた可能性を示し続けています。上記と同様のビジュアルで説明できる成功を収めたアプリケーションはたくさんあります。これらのアプリケーションのいくつかを見て、この記事を閉じましょう
機械翻訳
変換を行うためにエンコーダは必要ありません。同じタスクは、デコーダーのみのトランスフォーマーによって対処できます。
要約
これは、最初のデコーダーのみのトランスフォーマーがトレーニングされたタスクです。つまり、ウィキペディアの記事 (目次の前の冒頭セクションなし) を読み、それを要約するように訓練されました。記事の実際の冒頭部分は、トレーニング データセットのラベルとして使用されました。
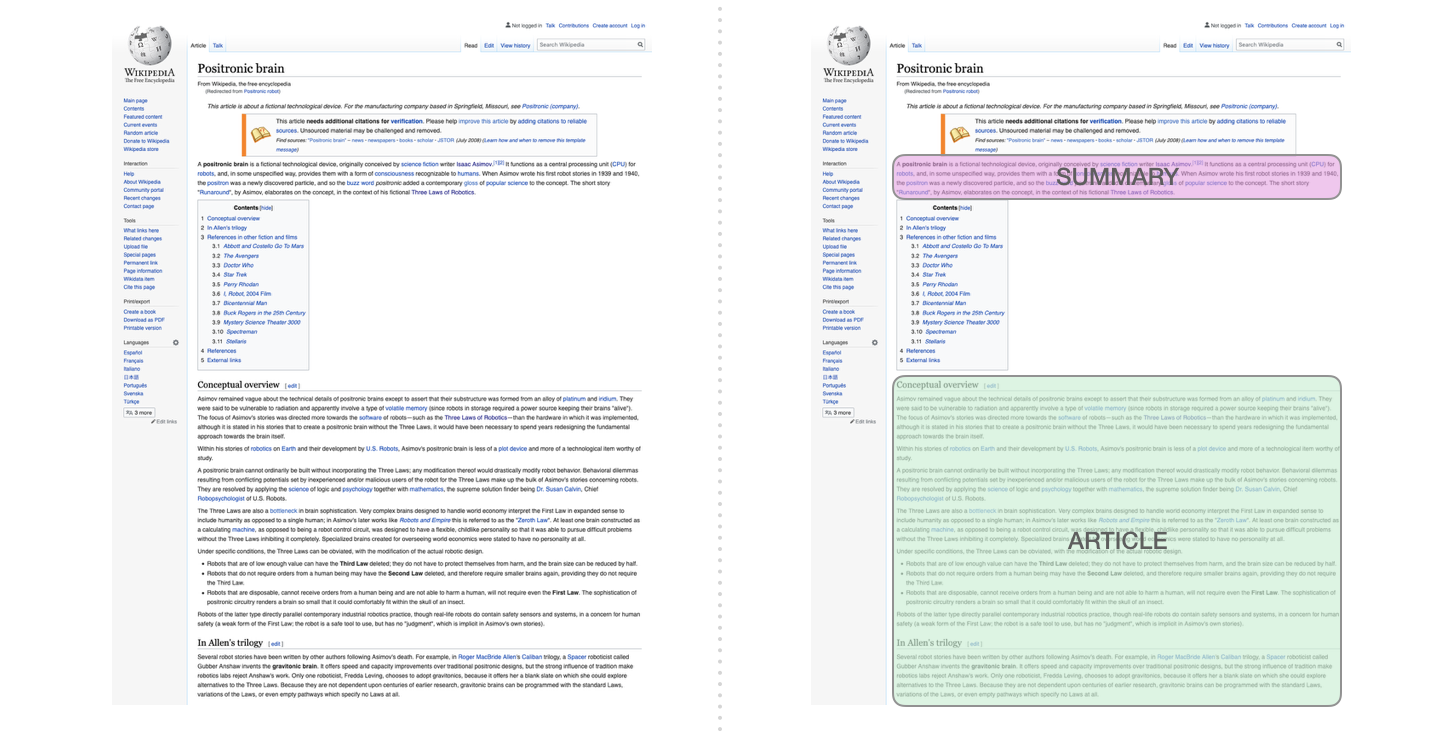
この論文は、ウィキペディアの記事に対してモデルをトレーニングしたため、トレーニングされたモデルは記事を要約することができました。
転移学習
単一の事前トレーニング済みトランスフォーマーを使用した効率的なテキスト要約のサンプルでは、デコーダーのみのトランスフォーマーが最初に言語モデリングで事前トレーニングされ、次に要約を行うために微調整されます。限られたデータ設定で、事前にトレーニングされたエンコーダー/デコーダー変換よりも優れた結果が得られることが判明しました。
GPT2 の論文では、言語モデリングでモデルを事前トレーニングした後の要約の結果も示されています。
ミュージックジェネレーション
Music Transformerは、デコーダーのみのトランスフォーマーを使用して、表現力豊かなタイミングとダイナミクスを持つ音楽を生成します。「音楽モデリング」は言語モデリングと同じです。モデルに教師なしの方法で音楽を学習させ、出力をサンプリングさせます (前述の「ランブリング」と呼ばれるもの)。
このシナリオで音楽がどのように表現されるかについて興味があるかもしれません。言語モデリングは、文字、単語、または単語の一部であるトークンのベクトル表現を通じて実行できることに注意してください。音楽演奏 (ここではピアノについて考えてみましょう) では、音符だけでなく、ベロシティ (ピアノのキーをどれだけ強く押すかの尺度) も表現する必要があります。
パフォーマンスは、これらの一連のワンホット ベクトルにすぎません。midi ファイルは、このような形式に変換できます。この論文には、次の入力シーケンスの例があります。

この入力シーケンスのワンホット ベクトル表現は次のようになります。
Music Transformer で自己注意を示している論文のビジュアルが気に入っています。ここにいくつかの注釈を追加しました。
![]()
「図 8: この曲は繰り返し三角形の輪郭を持っています。クエリは後者のピークの 1 つにあり、曲の最初までずっと、ピークの前のすべての高音に注意を払っています。」… “[The] 図は、クエリ (すべての注意線のソース) と以前の記憶に注意を向けていることを示しています (より多くのソフトマックス確率を受け取っているメモが強調表示されています)。注意線の色は、さまざまな頭に対応しています。ソフトマックス確率の重みの幅。」
この音符の表現がよくわからない場合は、このビデオをご覧ください。
結論
これで、GPT2 への旅と、その親モデルであるデコーダーのみのトランスフォーマーの調査を終了します。この記事を読んで、自己注意の理解が深まり、変圧器の内部で何が起こっているかをより理解できるようになることを願っています.

コメント